the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 15 Aug 2019
| 15 Aug 2019
Harmonization and comparison of vertically resolved atmospheric state observations: methods, effects, and uncertainty budget
Steven Compernolle
Tijl Verhoelst
Daan Hubert
Jean-Christopher Lambert
Many applications of atmospheric composition and climate data involve the comparison or combination of vertically resolved atmospheric state variables. Calculating differences and combining data require harmonization of data representations in terms of physical quantities and vertical sampling at least. If one or both datasets result from a retrieval process, knowledge of prior information and averaging kernel matrices in principle allows retrieval differences to be accounted for as well. Spatiotemporal mismatch of the sensed air masses and its contribution to the data discrepancies can be estimated with chemistry transport modeling support. In this work an overview of harmonization or matching operations for atmospheric profile observations is provided. The effect of these manipulations on the information content of the original data and on the uncertainty budget of data comparisons is examined and discussed.





The quality assessment and validation of atmospheric state observations largely rely on making comparisons with (reference) measurements of the same observable. On the other hand, data merging or fusion schemes involve the combination of observations from different sources, weighted by functions that mix uncertainties, information content aspects, and spatiotemporal (4-D) representativeness. And chemical data assimilation involves the comparison and/or combination of observations with modeling outputs. However, quantitative comparisons and combinations of atmospheric soundings are only possible when the observables are represented on the same vertical grid, within the same vertical range, and in identical units. Moreover, observations by different instruments also differ in their sensitivity to and representativeness of spatiotemporal features of the atmospheric field (i.e., resolution or smoothing differences) (Loew et al., 2017). The remote sensing of the atmosphere by spaceborne and ground-based instruments additionally consists of under-constrained inverse problems that mix necessary prior information into the retrieved atmospheric state profiles (Rodgers, 2000). Taking into account these differences in representation, location, and, if applicable, retrieval characteristics is needed for proper data combinations and comparative validation exercises using difference statistics and χ2 testing (Rodgers and Connor, 2003; von Clarmann, 2006).
Carried out in the context of several satellite validation studies (for Sentinel-5P, the European Space Agency's Climate Change Initiative, and the Satellite Application Facility on Atmospheric Composition Monitoring) and considering the exploration of advanced data fusion methods (Cortesi et al., 2018), with a view to harmonize practices across satellite missions and Earth Observation domains, this work is meant to provide an overview of existing approaches that allow estimating and potentially (partially) correcting for these observational differences in quantitative data comparisons. The uncertainties that are tied to these differences, as typically expressed in terms of covariance matrices, as a result are also (partially) removed from the uncertainty budget of the data comparison. All relevant difference error contributions are identified in the next section, where it has also been necessary to align some concepts and terminology that might not be identical across all atmospheric research communities. Section 3 then motivates why the difference error contributions must ideally be either quantified or corrected for in the difference statistics. Opting for the latter, an overview of harmonization (or homogenization) operations that match two atmospheric state datasets in terms of their representation, retrieval characteristics, and location is provided in Sect. 4. This section focuses on the harmonization algebra, while the reader is referred to the bibliography for specific examples using real data. The impact of the “matching” operations on the observations' information content and on the comparison uncertainty budget is discussed in Sects. 5 and 6, respectively.
When taking the difference of two vertically resolved atmospheric state observations, e.g., a measurement under study xs and a reference measurement xr that both aim for the same true state xt as the measurand, random and systematic measurement errors ϵ on both observations will lead to a non-zero difference vector Δϵ:
This equation only holds for observations that are exactly spatiotemporally co-located. Usually, however, the air masses that are sampled by both measurements do not match. This introduces a spatiotemporal (4-D) co-location mismatch error, which can be subdivided into a sampling difference error ϵΔsa (different nominal measurement location and time) and a smoothing difference error ϵΔsm (different 4-D air mass sensitivity) (Nappo et al., 1982; Lambert et al., 2013; Verhoelst et al., 2015). Assuming that both types of error are independent, the above becomes
For vertically resolved atmospheric state observations, a distinction can be made between the horizontal and vertical sampling and smoothing difference errors, next to their temporal counterparts, and , so that
If at least one of the observations is the result of a retrieval process, some retrieval contributions to the difference errors can be made explicit as well. For example each retrieved profile x that is obtained by an optimal estimation (OE) approach can be regarded as a weighted average between prior and measurement information (Rodgers, 2000):
where ϵ includes, next to (spectral) measurement errors, remote sounding errors like the retrieval parameter errors and forward model errors (Rodgers, 2000, Eq. 3.16). The latter as such also capture the uncertainty on the square weighting matrix A. This is the so-called averaging kernel matrix (AKM) that is determined by the prior profile shape (PS) xa, the prior constraint (PC) in terms of its covariance matrix Sa, and the retrieval process that yields a vertical smoothing and a measurement weight (MW) (also see next sections). Matrix I represents the identity matrix equal in size to the AKM. The following sections however are also valid for retrieval approaches that have xa=0, like in some Philips–Tikhonov regularization schemes, as the equations can easily be adopted accordingly. By inclusion of as retrieval difference errors, the observed difference Δx containing at least one retrieved product can be decomposed as follows:
Here Δϵ′ then contains both the known and unknown measurement errors and remote sounding errors (Rodgers, 2000; Povey and Grainger, 2015).
The Committee on Earth Observation Satellites (CEOS) defines validation as (1) “the process of assessing, by independent means, the quality of the data products” (International Organization for Standardization, 2014). Validation is also defined by international normalization bodies as (2) “the confirmation, through the provision of objective evidence, that specified requirements, adequate for an intended use, have been fulfilled” (Joint Committee for Guides in Metrology, 2012). In the atmospheric remote sensing literature, the validation exercise is also sometimes defined as (3) “to confirm that the theoretical characterization and error analysis actually represent the properties of the real data” (Rodgers, 2000) or (4) “to confirm the predicted accuracy estimator of that product” (von Clarmann, 2006). The predicted (or inductive or ex ante) uncertainty of the product under study is typically represented by an error covariance matrix , which means that uncertainty information is restricted to covariances and higher-order correlations are ignored. Two approaches are commonly applied in order to validate this uncertainty by comparison of the product under study with a reference data product that is characterized by an ex ante uncertainty Sr.
One can perform a so-called χ2 test to verify whether the difference between the study and reference products Δx is consistent (χ2∼1) with the predicted estimate of the total uncertainty on the difference SΔ (Rodgers and Connor, 2003; von Clarmann, 2006):
whereby L symbolizes the number of elements in Δx, and SΔ is the full sum of the covariance matrices of the errors that were previously identified, including as the ex ante uncertainty prediction of the study and reference products combined:
This expression assumes that the covariance matrices of the difference error terms are independent and are not already included in the ex ante covariance matrices. Equation (7) should be corrected for those which are. For an ensemble of N pairs of spatiotemporally co-located study and reference profiles, one can now either determine or one can replace the factors in Eq. (6) by statistical estimators. In the latter case a distinction between bias b (systematic) and precision p (random) tests can be made, whereby the combined root-mean-square uncertainty a as an estimator of the accuracy obeys (von Clarmann, 2006; Joint Committee for Guides in Metrology, 2008, 2012).
Secondly, one often directly quantitatively or qualitatively verifies whether a sample bias 〈Δx〉 as an estimator of the combined systematic error of the products is of the same order as the combined ex ante uncertainty on the mean difference, and whether the corresponding sample dispersion on the differences σ(〈Δx〉) as an estimator of the standard deviation around the bias (combined random uncertainty) is of the same order as the combined ex ante random uncertainty on the difference. Unfortunately it is often overlooked that also here the combined random and systematic components of all difference error contributions to SΔ should actually be taken into account, and not only those inductively provided with the study and reference data products through Ss and Sr, respectively.
Irrespective of the method used, a full assessment and quantification of all contributions to the difference error SΔ are necessary to close the uncertainty budget and perform a proper comparative validation. Alternatively however, one can reduce the (number of) difference error terms by applying harmonization operations on the study and/or reference profiles. Using matching manipulations, a difference Δx is thereby replaced by a difference Δx′ that contains fewer, or at least reduced, difference error contributions. Furthermore these omitted contributions should no longer to be considered in . On the other hand, note that profile matching operations in turn introduce manipulation (difference) errors and possibly ancillary data uncertainties.
This section provides an overview of profile matching manipulations. A distinction is made between representation matching (relating to the vertical grid, vertical quantities, and their units), vertical smoothing matching (cf. vertical resolution of the measurement), retrieval matching (cf. impact of prior information), and spatiotemporal co-location matching. Because of the focus on vertically resolved atmospheric state observations, horizontal and vertical sampling and smoothing issues are discussed separately.
4.1 Vertical representation matching (mandatory)
The matching of the vertical representation of the study and reference profiles is an unavoidable operation to make difference calculations possible in the first place. The vertical representation includes the vertical sampling and coordinate (altitude, pressure, geopotential height, or other) and the atmospheric state quantity (volume mixing ratio, number density, partial column, or other). A representation conversion may introduce a bias and reduce the precision due to uncertainties in the ancillary data and data manipulations, which actually should be taken into account in the comparison's uncertainty budget (see Sect. 6).
4.1.1 Vertical quantity matching
When changing between concentration-type quantities like number density and volume mixing ratio, a diagonal level-by-level unit conversion matrix M can be constructed straightforwardly (e.g., Keppens et al., 2015, Table B1). The quantity-matching operation for a vertical profile x, with corresponding ex ante covariance matrix S and possibly averaging kernel matrix A, is then easily achieved by matrix multiplication (Keppens et al., 2015):
Note that these operations have no effect on the fractional covariance matrix, nor on the fractional (or logarithmic) averaging kernel matrix that is required for information content studies (see Keppens et al., 2015 and Sect. 5).
When going from a concentration-type representation on levels to one between levels (i.e., on layers, like partial columns), one can choose the integration boundaries either on the given levels or in between them with the exception of the outer edges, resulting in a rectangular or square conversion matrix M, respectively (Keppens et al., 2015, Table B1):
and
with
Here h has been used as a generalization of the vertical coordinate (altitude, pressure or other) with L elements, while u is the relevant unit conversion constant. Note that in contrast with Eq. (9), the inverse of M in Eq. (10) is not under-constrained, which favors the latter at the small price of the need for an h′.
4.1.2 Vertical sampling matching
The number of levels (for point-like concentration values) or layers (for vertically integrated column values) and their vertical locations or boundaries have to be identical for two profiles to be quantitatively compared. One can opt for an explicit vertical range matching of the two profiles first, e.g., by vertical clipping of the one or by extension by use of a climatology of the other. The latter can be applied when later profile operations require knowledge of the atmospheric state over its full vertical range (Keppens et al., 2015). When vertical range matching is skipped, vertical sampling or grid-matching operations – often called regridding – automatically limit the height range of the input profile grid to its vertical overlap region with the target profile grid.
Several regridding approaches are in use, although their application typically can depend on units and/or the vertical resolution discrepancy between the input and target grids.
-
Straightforward regridding by (linear or other) interpolation only works appropriately, i.e., with minimum information loss, when going from a coarser-resolution input grid to a finer-resolution target grid. Although the corresponding interpolation matrix W is not square, it is applied in an identical way as the unit conversion matrix M in Eq. (8):
As the inverse of a non-square matrix is ill-posed, its definition depends on the norm one wishes to minimize. Opting for a simple least squares difference between the input and target profiles yields (Rodgers, 2000). The elements of W are determined by the interpolation function one applies, which introduces an additional term in the uncertainty budget (see Sect. 6).
-
In order not to suggest a vertical resolution that is misleadingly much higher than the effective vertical resolution of (one of) the observations, atmospheric state profile comparisons are often made on the vertical grid of the product with the coarsest sampling. When consequently the input grid has a finer resolution than the target grid, one can easily invert the problem by constructing an interpolation matrix W for going from the target grid to the input grid, and then applying the regular regridding formulas for . This approach is denoted as pseudo-inverse (linear or other) regridding. When going from a fine to a coarse vertical sampling, this method approximately conserves the atmospheric constituent’s mass (vertically integrated amount) over a wavelet-like vertical window function (also see Sect. 5).
-
In practice vertical sampling definitions might change in time, or one might not know beforehand whether the target grid is coarser than the input grid or vice versa, or both grids may be similar. Calisesi et al. (2005) have therefore proposed to combine both of the previous methods by first constructing two interpolation matrices, W1 and W2 respectively, going from the input and target grids to a conjoint super grid that is the resorted union of the input and target grids. As a result, one can generally apply vertical sampling matrix as before.
-
One might instead prefer the total vertical column amount to be conserved during the regridding operation. Such mass-conserved regridding is easily achieved for partial column quantities, whether going from finer to coarser resolution or vice versa. It is sufficient to construct an overlap matrix that contains the fractions of how much each target grid layer is covered by an input grid layer (Langerock et al., 2015). Assuming that the ith output grid layer overlaps with the jth input grid layer, the corresponding element of the conversion matrix is the following interpolation factor
with Δhin,j the input layer thickness and the indices U and L indicating the layers' upper and lower height bounds, respectively. Note that this expression implicitly makes use of the conjoint super grid (see previous), allowing broad usage of this approach. If there is no overlap between target layer i and input layer j, then W(i,j) equals 0. The coefficients of the conversion matrix therefore satisfy .
-
Total mass-conserved regridding of concentration-type quantities defined on vertical levels or as vertical averages, as is often the case in model fields, is somewhat less straightforward. Before being able to apply the conversion matrix as defined in the previous expression, the point-like concentration values of the input profile must be converted to vertically integrated values, and after the subsequent mass-conserved regridding operation a conversion to the initial units is needed. A combination of Eq. (13) with a forward and backward conversion by use of Eq. (8) including M defined by Eq. (10) (with well-defined inverse) is hence required, although this can be achieved in arbitrary units (i.e., without the need for the unit conversion constant u):
Here Min and Mout are the conversion matrices for the input and output grids to their layer representations, respectively, and W is the regular mass-conserved regridding matrix of Eq. (13).
4.2 Vertical smoothing matching
The vertical correlation of atmospheric measurement or retrieval quantities results from the allocation to neighboring levels (layers) of concentrations (columns) that are in fact obtained from vertically overlapping probed air masses. Especially for profile retrievals that have more retrieval levels than independent degrees of freedom in the measurement, the vertical smoothing of the spectral measurement information by the retrieval can be large. As the algebraic inversion of a retrieved profile's vertical smoothing is typically an ill-posed problem, vertical smoothing matching is ideally achieved by imposing an estimator of the coarser height-dependent window smoothing function to each level (layer) of the atmospheric state profile with the smaller window smoothing.
The smoothing window estimator can take any custom-defined shape, but in practice typically a box, triangular, or Gaussian-like function is applied. The window function in any case has to be normalized to unity, while the function width determines the extent of the vertical smoothing effect. This extent is chosen in agreement with the estimated vertical resolution of the coarser-smoothed atmospheric observation, usually going from a few to several tens of kilometers (Keppens et al., 2015). The smoothing functions additionally have to be discretized to the number of target profile levels (layers) for application of the vertical smoothing matching by matrix multiplication, , with the rows of V containing the level-specific smoothing functions. The averaging kernel matrix here does not transform in the same way as a representation matching operation (as in Eqs. 8 and 12), but is given by as a unilateral smoothing of the averaging kernel (AK) matrix itself (Rodgers and Connor, 2003). On the other hand, the regular conversion formula for the target profile’s covariance matrix still holds true, as the covariance represents a quadratic quantity.
For retrieved atmospheric state profiles, the best and already discretized estimators of the vertical smoothing functions are provided by the averaging kernel matrix rows (Rodgers, 2000). These vectors are automatically normalized to unity for some Philips–Tikhonov-type regularization techniques that have xa=0 but are to be explicitly normalized for optimal estimation and other retrievals that have AKM row sums different from one. The resulting unit-sensitivity averaging kernels (i.e., with unit row sums) are denoted as A1. Usually vertical sampling matching, either of the retrieved profile’s averaging kernel matrix or of the target state vector, is required before one can apply V=A1 (also see Sect. 4.5).
4.3 Retrieval matching
Attempting to harmonize two atmospheric state products whereby at least one is the result of a retrieval process, one has to consider differences in measurement weights, prior profile shapes, and prior constraints between both products. These differences can be (partially) corrected for in two ways. Either one imposes the retrieval artifacts of one product on the other, or one eliminates the retrieval artifacts and associated uncertainties from the retrieved product(s) at the cost of vertical resolution. Both options are discussed in the following two subsections, respectively.
4.3.1 Imposing retrieval artifacts
-
Measurement weight matching. The vertical sensitivity of an atmospheric state retrieval is defined as the column vector of its averaging kernel row sums. It is given by Au if u represents the vertical unit vector and can be considered an estimator of the height-dependent fraction of the retrieval that comes from the measurement, rather than from the prior profile (Rodgers, 2000). One can thus define a diagonal measurement weight matrix WM (or prior weight matrix I−WM) by diag(WM)=Au, so that A=WMA1 or . The last expression provides the most straightforward calculation of the AK-based vertical smoothing matrix V in the previous section. The measurement weight harmonization operation that matches the sensitivity of an atmospheric state with the measurement weight WM of a given retrieved state is thus given by , with . Here , as the diagonal matrix WM can be considered as merely a vertically resolved conversion constant.
-
Prior matching. Rodgers (2000, Eq. 10.48) provides an expression for replacing the prior constraint Ra and profile shape xa within a given retrieval by and , respectively:
whereby the prior constraint is typically, but not necessarily, given by the inverse of the prior covariance matrix, . If only the prior’s profile shape xa is substituted by (i.e., for ), the prior matching formula simplifies to the rather intuitive (Rodgers and Connor, 2003, Eq. 10)
by taking into account that (Rodgers, 2000, Eq. 2.79). The latter moreover shows that . The prior-changed covariance matrix S′ is obtained by substituting Sa by in the retrieval's expression for S (for example Rodgers, 2000, Eq. 2.27): .
-
Re-optimized prior matching. By changing the prior in a given retrieval, the resulting atmospheric state profile x′ and its AKM will no longer provide an optimally estimated (i.e., with minimal retrieval gain function) representation with respect to the new constraint. Hence re-optimization of the prior-matched profile might be required. When , this can be achieved by (Rodgers and Connor, 2003, Eq. 18)
whereby the atmospheric state vector x on the right-hand side is taken from the output of the prior matching operation in Eq. (16). The re-optimized prior matching that combines Eqs. (16) and (17) thus takes the form , with and like a vertical smoothing operation. Just as before, correspondingly. Ridolfi et al. (2006, Eq. 8) obtained the same conversion matrix P by constructing an optimal interpolation method, i.e., an optimization through trace(SΔ) minimization of combined vertical sampling and smoothing matching operations (hence the non-square AKMs and preceding A1 in their expression). However, based on the complete data fusion framework, Ceccherini et al. have been able to construct a more general re-optimized prior matching operation that is valid for all new prior profile shapes and constraints (Ceccherini et al., 2014, Eq. 7):
This expression even holds when and are defined on a different vertical grid than the input profile x. In that case it is sufficient to replace A by AW* in Eq. (18) (also in P) with W, a regridding matrix as defined in Sect. 4.1.2 (Ceccherini et al., 2018).
-
Averaging kernel smoothing. In practice the covariance matrices that are needed in Eqs. (17) and (18) are not always provided to data users, or implementation of the (re-optimized) prior matching is not preferred. One can however avoid these operations by equalling to the prior of one of the profiles in a comparison and then applying a vertical smoothing matching and measurement weight matching on this profile by use of the second profile’s averaging kernel matrix. In doing so, only the second profile has to be prior-corrected, resulting in only one non-optimal representation, while this non-optimality and the initial prior constraint of the second profile are enforced on the first profile and therefore drop out of the difference comparison. This whole process thus combines vertical smoothing matching with V=A1, measurement weight matching with diag(WM)=Au, and prior matching that does not require re-optimization (Eq. 16). By, for example, comparing a vertically smoothed and measurement weight-corrected reference profile with a prior shape-corrected profile under study one obtains (omitting any necessary vertical representation matching)
If additionally the reference profile results from an in situ measurement or model (), this equation can just as well be inferred by considering and imposing the satellite retrieval on the reference profile, meaning that the unknown true profile xt is replaced by xr in Eq. (4) (without the error term):
It is typically the latter interpretation that is referred to as averaging kernel smoothing (of xr). The term however also applies when this reference profile is a retrieved product as well. In that case one can even apply symmetrical smoothing of both the satellite and reference profiles if they show comparable vertical smoothing (Rodgers and Connor, 2003; von Clarmann and Grabowski, 2007)
for prior matching to a common xa,c. This expression simplifies to Eq. (19) for and Ar=I.
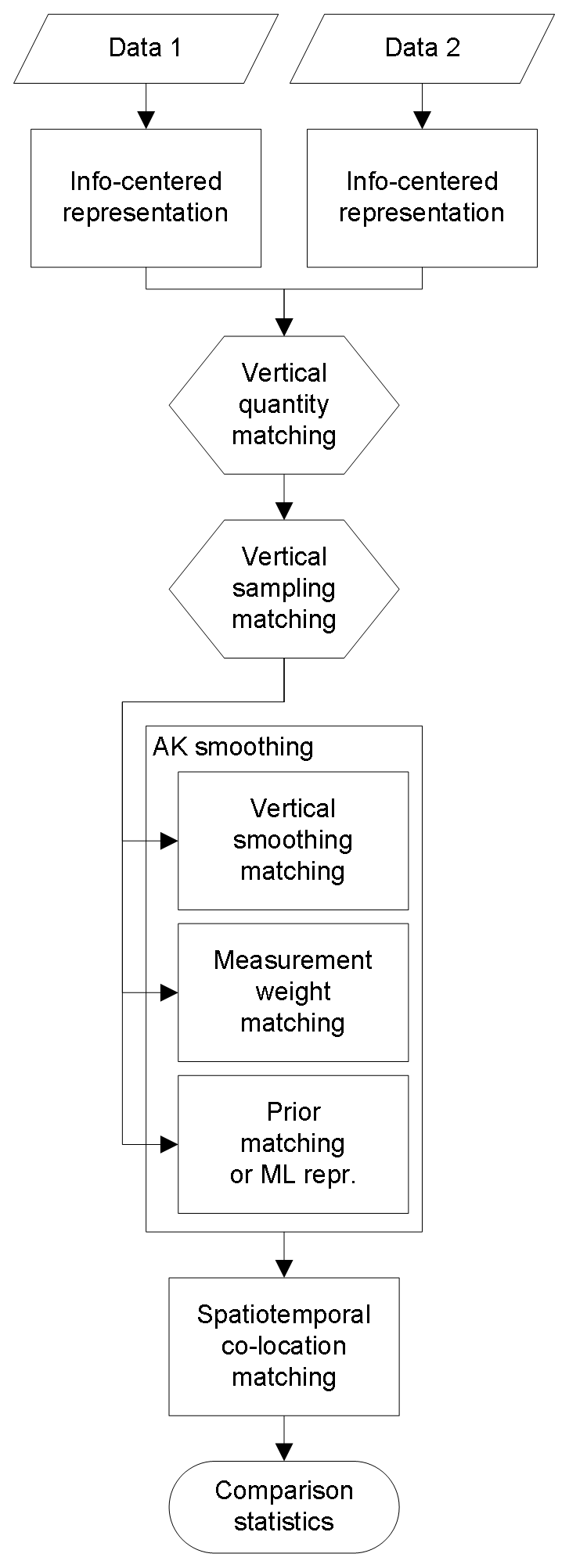
Figure 1Profile harmonization flowchart, indicating the order of the matching operations outlined in the text. Rectangular boxes are optional, while hexagons are mandatory. The maximum likelihood (ML) representation has here been included as a prior matching operation with .
4.3.2 Removing retrieval artifacts
-
Maximum likelihood representation. The maximum likelihood representation (MLR) of a retrieved atmospheric state profile corresponds to the retrieval in the absence of explicit prior information, i.e., the retrieval for Ra=0 (Rodgers, 2000). One can thus easily convert a given retrieved profile to its maximum likelihood representation by performing a prior matching operation as in Eq. (15) with (Rodgers, 2000; von Clarmann et al., 2015):
The resulting covariance matrix is given by , while the averaging kernel matrix becomes the unit matrix, making re-optimization meaningless. This does however not mean that the MLR is fully unconstrained, as it is still implicitly constrained by its vertical grid and the related interpolation convention (von Clarmann and Grabowski, 2007).
-
Information-centered representation. In order to explicitly remove all prior information from a given retrieval and hence simulate a direct measurement with all levels or layers representing one degree of freedom, the prior constraint replacement operation has to be combined with a vertical regridding operation while also setting (von Clarmann and Grabowski, 2007):
By insertion of the transposed regridding matrix and its pseudo-inverse, one obtains
In order to remove all prior information from the retrieval outcome, one thus has to determine W and that impose the hard constraint non-trivially instead of using the soft MLR constraint (von Clarmann and Grabowski, 2007). The difficulty of this approach lies in the determination of these two matrices in agreement with (i.e., causing minimal loss) the number of independent pieces of information or degrees of freedom in the initial measurement, which is given by trace(A). The study from von Clarmann and Grabowski (2007) provides methods to do so – in both staircase and triangular representation – that are rather extensive and therefore not reproduced here. Equation (24) can also be obtained from Eq. (18) including W*, while it is in agreement with Rodgers (2000, Eq. 10.50) only if the latter’s back-transformation to the original grid is omitted. Rodgers therefore still indicates his representation as a maximum-likelihood solution, while here the term information-centered representation by von Clarmann and Grabowski (2007) is adopted. Note however that these two references have considered opposite directions in the definition of their respective regridding matrices W. Again , while the covariance matrix is now given by in agreement with the prior matching expression upon addition of a regridding operation.
4.4 Spatiotemporal co-location matching
As described in the previous sections, vertical sampling and effective resolution differences can be virtually eliminated by applying appropriate regridding and smoothing procedures, respectively. The underlying requirement however is that the vertical dimension within the measurement range is nearly continuously sampled or, phrased differently, that neither the study nor the reference profile is vertically highly under-sampled. This ensures that neither instrument is blind to significantly variable parts of the profile, as only then can interpolation errors be kept to a minimum. Alternatively, interpolation difference errors could be small if both instruments have the same under-sampling pattern, but this hardly occurs in practice.

Figure 2Regridding window functions for the four vertical sampling matching operations discussed in Sect. 4.1.2, going from a fine grid (0 to 100 in steps of one) to a coarse grid (0 to 100 in steps of 100∕13) that only overlaps at the vertical edges (a.u.). The seventh row of each regridding matrix with dimension 14×101 is plotted (columns 20 to 80 only). For pseudo-inverse and super-linear regridding these matrix elements are never zero, but of the order of 10−6 at the edges.
In the horizontal and temporal dimensions, the sufficient-sampling requirement is usually far from satisfied for vertically resolved atmospheric state observations, in particular for ground-based measurements. Except for some specific measurement campaigns, station-to-station distances are usually much larger than the horizontal representativeness of the measurements, and the typical sounding frequencies (e.g., weekly) are much coarser than the characteristic measurement duration (minutes to hours) and timescale of atmospheric variability (Nappo et al., 1982). Consequently, it is usually impossible to horizontally smooth data from multiple ground-based reference stations to the resolution of the measurement under study, just as it does not make sense to interpolate temporally between, for example, weekly soundings. On the other hand, horizontal smoothing can occasionally be achieved for satellite-to-satellite comparisons that have horizontal averaging kernels available (Lambert et al., 2013). Without the possibility to regrid to a common horizontal and/or temporal grid, comparisons must be done for co-located pairs, whereby the co-location criteria are designed to ensure minimal co-location mismatch errors in Eq. (5), i.e., minimal differences in the measurements due to a different horizontal and temporal sampling and smoothing of the variable and inhomogeneous atmosphere.
Table 1Matching operations overview table for vertically resolved atmospheric state observations (order of appearance in the text). The averaging kernel (AK) smoothing operation shows the exemplary case for and Ar=I.

Table 2Impact of matching operations on the information that is contained in the fractional averaging kernel matrix, as expressed by the DFS = trace(A) and the vertical sensitivity Au (order of appearance in the text). The averaging kernel (AK) smoothing operation shows the exemplary case for and Ar=I.

It is beyond the scope of this work to provide a review of all potential co-location methods, which range from simple space and time constraints to more geophysical constraints (e.g., based on potential vorticity), and even Lagrangian trajectory calculations to match as much as possible the measured air masses (Loew et al., 2017). In this context, it is important to realize that the actual four-dimensional extent of the measurement sensitivity is not easily captured in the metadata (approximations such as an effective measurement location are often too crude). Instead, so-called observation operators can be used to improve the air mass matching (Lambert et al., 2013; Verhoelst et al., 2015). These geometric parametrizations of the four-dimensional extent of the measurement sensitivity are based on physical considerations and – if possible – radiative transfer and retrieval models. They can for instance be derived from dedicated calculations of horizontal averaging kernels (von Clarmann et al., 2009).
Despite these attempts to optimize the co-location criteria, some irreducible co-location mismatch usually still affects the comparisons, adding non-negligible random and systematic errors to the difference statistics, and thereby hampering the interpretation of the differences in terms of the quality of the measurements and their reported uncertainties. Several approaches to quantify these co-location difference errors exist; see Verhoelst et al. (2015) and Fassó et al. (2017) for an overview and some case studies. Particularly appealing is the option to estimate the individual errors from model-based simulations. In this approach, the measurements are simulated by applying the observation operators, initialized with the real measurement metadata, on a gridded representation of the atmosphere. The vertically resolved difference Δm between the simulated measurement under study ms and the simulated reference measurement mr then provides an estimate of the horizontal and temporal co-location mismatch error profile:
This co-location mismatch error estimate can be used to horizontally and temporally match the observed profiles (von Clarmann, 2006, Eq. 15):
The use of model data however also introduces some model uncertainty in the comparison results, meaning that this procedure only makes sense when the model uncertainty is (expected to be) smaller than the (spread on the) co-location mismatch errors. Moreover, a residual co-location difference error is still present, caused by finer structures in the sampling and smoothing of the observations than those accounted for by the model. This residual error can be quantified by use of an additional reference dataset that has a finer resolution than the model (von Clarmann, 2006), but the quantification procedure is not expanded here. Combining the model uncertainty and (possibly negligible) residual spatiotemporal co-location difference error into SΔm, one simply has . Although strictly speaking the averaging kernel matrix is no longer valid for the spatiotemporally shifted profile x′, one can estimate the effect of the model uncertainty that is introduced during the matching operation on the AKM by taking .
Table 3Impact of matching operations on the comparison uncertainty budget SΔ (order of appearance in the text). The residual covariance of the vertical sampling matching includes the regridded vertical smoothing . The averaging kernel (AK) smoothing operation shows the unidirectional case.

4.5 Overview and order of operations
An overview of the atmospheric state profile matching operations discussed in this work is listed in Table 1 (order of appearance). The matrix algebra that is required to obtain x′, S′, and A′ is provided for each operation. The flowchart in Fig. 1, on the other hand, shows the preferred order of the matching operations that possibly precede the comparison of two atmospheric state profiles under study. Vertical representation matching (of quantities and grids) is thereby mandatory, but the full elimination of retrieval artifacts by changing to the information-centered representation has to take place first, as it also includes a change in the profile's vertical sampling. Optional vertical smoothing matching, measurement weight matching, and prior matching follow after the representation matching. All three can be combined into the so-called averaging kernel smoothing operation, or one can opt for a conversion to a maximum-likelihood representation for one or both profiles. Both options do not require re-optimization operations.
Keppens et al. (2015) have discussed the possibility to perform averaging kernel smoothing by multiplying a row-interpolated averaging kernel matrix with a full high-resolution ground profile instead of regridding the ground profile first as suggested in Fig. 1. The former approach maximally exploits the fine-gridded reference measurement without adding information to the retrieval data (Ridolfi et al., 2006). On the other hand however, this method additionally requires row renormalization of the interpolated AKM in order to conserve the vertical sensitivity of the averaging kernel matrix (Keppens et al., 2015, Eq. 11). Only for mass-conserved regridding of partial column quantities is the AKM renormalization already included by definition. In that case both approaches are equivalent, as one has . Keeping all vertical sampling matching operations before any averaging kernel smoothing therefore in general is the most straightforward approach. This order of operations moreover avoids the smoothing error pitfalls as discussed by von Clarmann (2014).
While intended to merely remove uncertainty contributions from eventual atmospheric state profile difference statistics, the harmonization operations discussed in this work obviously also impact the remaining covariance (matrix) and the information that is contained within a retrieval's averaging kernel matrix. First of all, from the discussion on vertical smoothing matching one can observe that in fact all operations that include a multiplication with a non-diagonal conversion matrix also impose a vertical smoothing on the vertical profile and its covariance and averaging kernel matrices. Especially the vertical sampling matching operation combines information from several input grid levels into a single output grid level by definition. For linear and mass-conserved regridding operations, the associated vertical smoothing windows are approximately triangular and square, respectively, with an extent that is limited to adjacent grid points (see Fig. 2). When going from a fine to a coarse grid however, the use of inverse or double (linear) interpolation over a conjoint super grid results in a wavelet-shaped vertical smoothing function that can extend up to the full vertical profile range. This is due the pseudo-inverse matrix that is involved, as demonstrated in Fig. 2.
Vertical quantity matching by use of a diagonal conversion matrix will not introduce a vertical smoothing effect, but affects the covariance matrix and the averaging kernel matrix nevertheless. This is a result of these matrices being typically provided in absolute and, thus, unit-dependent numbers. One can avoid this unit dependence by switching to fractional representations of the covariance and averaging kernel matrices instead. These are given by and , respectively (Keppens et al., 2015, Eqs. 3 and 4). Note that the latter automatically results from a logarithmic retrieval. Because of their invariance under (matrix-diagonal) unit conversions, such fractional averaging kernel matrices are preferred for information content studies (Keppens et al., 2015). Fractional kernel representations are therefore also assumed in Table 2 that summarizes how a retrieval's degrees of freedom in the signal (DFS), calculated as the AKM trace, and its vertical sensitivity, calculated as the AKM row sum vector, are altered by each harmonization operation.
The harmonization operations presented in this work are intended to enable the calculation of profile difference statistics and to eliminate uncertainty contributions from the total uncertainty budget as expressed by Eq. (7). Table 3 lists for each profile matching operation the covariance that is thereby removed (first column), how the ex ante covariance of the harmonized atmospheric state product is altered (second column), and what uncertainty is possibly introduced by the operation or remains as a residual despite the matching (third column).
It is clear that the vertical representation harmonization operations actually do not remove uncertainty from the full budget but are required for difference calculations of atmospheric state vectors with equal units and lengths. These operations affect the product covariance and moreover introduce auxiliary representation conversion uncertainty SQ and an additional vertical smoothing difference uncertainty (see regridding impact discussion in previous section and next paragraph), respectively. The former however is usually hard to quantify, and therefore often neglected. The model uncertainty SΔm that is introduced by the co-location matching operation (see Sect. 4.4) is of the same nature as SQ but preferably better characterized and explicitly taken into account as the model correction of a vertical profile leaves the associated ex ante product uncertainty unchanged: . Note that despite these additional uncertainties one evidently expects the matching operations to reduce the overall difference covariance. For sufficiently fine-gridded models the co-location matching could in principle also account for vertical sampling and smoothing differences, but this is hardly feasible in practice.
Two atmospheric state products with different vertical smoothing V1 and V2 have a vertical smoothing difference covariance in their combined uncertainty budget (e.g., Rodgers and Connor, 2003; von Clarmann and Grabowski, 2007). Here SC represents the comparison ensemble's covariance matrix, which in practice is often replaced by one of the two ex ante product covariance matrices or their sum. Upon vertical smoothing matching, e.g., by enforcing the vertical smoothing of the first on the second, the vertical smoothing difference is actually not fully removed, as a residual smoothing difference covariance remains:
or for symmetrical smoothing. Hence only the vertical smoothing of an ideal measurement with V2=I fully eliminates the vertical smoothing difference error (von Clarmann and Grabowski, 2007). It is the latter case that typically occurs for the vertical smoothing of model data and in situ reference data. When also considering vertical sampling matching, e.g., of the second product, V2 has to be replaced by WV2W* in Eq. (27) (von Clarmann, 2014).
For the (asymmetrical) averaging kernel smoothing operation, the expression in Eq. (27) has been modified to include the study and reference product AKMs. This harmonization operation also includes a measurement weight matching and a prior matching (see Sect. 4.3 and Fig. 1). Only the residual smoothing difference error covariance thus remains. The measurement weight matching actually consists of a rescaling and does therefore not introduce a new covariance term. Non-optimal prior matching on the other hand corrects for differences in prior profile shape and prior constraint, but as a result changes the measurement weight difference covariance to . Re-optimization of the prior-corrected state by use of Eq. (17) corrects for this measurement weight difference yet alters the vertical smoothing difference error as a result.
In terms of the uncertainty contributions that are removed from the full covariance of the difference, the AK smoothing operation is equivalent to the re-optimized prior matching (Eq. 18) and to switching to the information-centered representation beforehand. While for the former only a residual vertical smoothing difference error defined by P remains, the latter operation changes the vertical sampling difference covariance due to the inherent regridding operation (which upon subsequent vertical sampling matching is replaced by a vertical smoothing difference error). As demonstrated by von Clarmann and Grabowski (2007, Eq. 58), the information-centered representation yields an additional residual smoothing difference error if the variability of the true state is not sufficiently well characterized by S′ (not assumed here). The maximum likelihood representation aims at removing all prior information (including vertical smoothing and measurement weight), but actually is still implicitly (prior-)constrained by its vertical grid (see Sect. 4.3). Therefore a residual vertical smoothing difference and prior constraint difference contribution must be considered in the uncertainty budget.
In the context of data comparisons as performed in satellite validation and of data combinations through assimilation or fusion, this work discusses the most frequent methods for the harmonization of vertically resolved atmospheric state observations in a conceptually and terminologically aligned framework. The harmonization of two profiles' representations is mandatory for data comparisons and for proper quantitative χ2 testing of the resulting total difference covariance. Other data manipulations are needed to reduce the uncertainty budget of the comparison by minimizing the contributions due to differences in retrieval characteristics and spatiotemporal co-location. A total of 10 matching operations have been identified from the literature and expressed in a consistent way using common matrix algebra. These operations include procedures for converting the ex ante covariance matrix and the averaging kernel matrix (for retrieved products) associated with each atmospheric profile. Therefore the effect of each harmonization operation on the information content of a retrieved product, as calculated from its AKM, has also been discussed. Finally, which terms of the error covariance are removed from the full comparison uncertainty budget by each harmonization operation and what covariance remains as a residual or is introduced as a result have been examined. Concerning the covariance terms removed, averaging kernel smoothing appears to be equivalent to re-optimized prior matching and to switching to the information-centered representation beforehand, which both, however, are more difficult to practically implement. These operations only leave a residual smoothing difference error in the comparison (after regridding to a joint vertical grid for the latter). In combination with co-location matching by use of model data, these three approaches reduce the difference covariance to its minimum of the form .
No research data have been used in this theoretical overview work. The plots in Fig. 2 have been created from demonstrative matrices whose construction is explained in the text and caption.
AK wrote the majority of the text. SC initiated Sect. 5 and Fig. 2. TV wrote Sect. 4.4. DH verified the algebra and text consistency. J-CL is coordinator of this research.
The authors declare that they have no conflict of interest.
This article is part of the special issue “Towards Unified Error Reporting (TUNER)”. It is not associated with a conference.
The authors would like to acknowledge Thomas von Clarmann, Simone Ceccherini, Nicola Zoppetti, and Viktoria Sofieva for helpful discussions.
Parts of the reported work were funded by the AURORA project supported by the Horizon 2020 EU Research and Innovation program (call: H2020-EO-2015; topic: EO-2-2015) under grant agreement no. 687428, by ESA via the CCI-ECV Ozone Phase 2 project, and jointly by the Belgian Federal Science Policy Office (BELSPO) and ESA via the ProDEx project TROVA (PEA 4000116692, supporting S5PVT AO ID 28587 CHEOPS-5p). This work builds on the versatile satellite validation system Multi-TASTE that was developed in several heritage projects and refined within the EU FP7 Project Quality Assurance for Essential Climate Variables (QA4ECV; grant no. 60740) and EU H2020 project Gap Analysis for Integrated Atmospheric ECV CLImate Monitoring (GAIA-CLIM; grant no. 640276).
This paper was edited by Doug Degenstein and reviewed by two anonymous referees.
Calisesi, Y., Soebijanta, V. T., and van Oss, R.: Regridding of remote soundings: Formulation and application to ozone profile comparison, J. Geophys. Res., 110, 1–8, https://doi.org/10.1029/2005JD006122, 2005. a
Ceccherini, S., Carli, B., and Raspollini, P.: The average of atmospheric vertical profiles, Opt. Express, 22, 24808–24816, https://doi.org/10.1364/OE.22.024808, 2014. a
Ceccherini, S., Carli, B., Tirelli, C., Zoppetti, N., Del Bianco, S., Cortesi, U., Kujanpää, J., and Dragani, R.: Importance of interpolation and coincidence errors in data fusion, Atmos. Meas. Tech., 11, 1009–1017, https://doi.org/10.5194/amt-11-1009-2018, 2018. a
Cortesi, U., Ceccherini, S., Del Bianco, S., Gai, M., Tirelli, C., Zoppetti, N., Barbara, F., Bonazountas, M., Argyridis, A., Bós, A., Loenen, E., Arola, A., Kujanpää, J., Lipponen, A., Wandji Nyamsi, W., van der A, R., van Peet, J., Tuinder, O., Farruggia, V., Masini, A., Simeone, E., Dragani, R., Keppens, A., Lambert, J.-C., van Roozendael, M., Lerot, C., Yu, H., and Verberne, K.: Advanced Ultraviolet Radiation and Ozone Retrieval for Applications (AURORA): A Project Overview, Atmosphere, 9, 454, https://doi.org/10.3390/atmos9110454, 2018. a
Fassó, A., Verhoelst, T., and Lambert, J. C.: Measurement mismatch studies and their impact on data comparisons. EC Horizon2020 GAIA-CLIM technical Report / Deliverable D3.4, Tech. rep., University of Bergamo, available at: http://www.gaia-clim.eu (last access: 13 August 2019), 2017. a
International Organization for Standardization: ISO/TS 19159-1:2014 Geographic information – Calibration and validation of remote sensing imagery sensors and data – Part 1: Optical sensors, Tech. rep., ISO, available at: https://www.iso.org/standard/60080.html (last access: 13 August 2019), 2014. a
Joint Committee for Guides in Metrology: Evaluation of measurement data – Guide to the expression of uncertainty in measurement, Tech. rep., JCGM, available at: http://www.bipm.org/utils/common/documents/jcgm/JCGM_100_2008_E.pdf (last access: 13 August 2019), 2008. a
Joint Committee for Guides in Metrology: International Vocabulary of Metrology – Basic and General Concepts and Associated Terms, Tech. rep., JCGM, available at: http://www.bipm.org/en/publications/guides/vim.html (last access: 13 August 2019), 2012. a, b
Keppens, A., Lambert, J.-C., Granville, J., Miles, G., Siddans, R., van Peet, J. C. A., van der A, R. J., Hubert, D., Verhoelst, T., Delcloo, A., Godin-Beekmann, S., Kivi, R., Stübi, R., and Zehner, C.: Round-robin evaluation of nadir ozone profile retrievals: methodology and application to MetOp-A GOME-2, Atmos. Meas. Tech., 8, 2093–2120, https://doi.org/10.5194/amt-8-2093-2015, 2015. a, b, c, d, e, f, g, h, i, j
Lambert, J.-C., De Clercq, C., and von Clarmann, T.: Comparing and merging water vapour observations: A multi-dimensional perspective on smoothing and sampling issues, vol. 10 of ISSI Scientific Report Series, chap. 10, 215–242, Springer-Verlag New York, https://doi.org/10.1007/978-1-4614-3909-7, 2013. a, b, c
Langerock, B., De Mazière, M., Hendrick, F., Vigouroux, C., Desmet, F., Dils, B., and Niemeijer, S.: Description of algorithms for co-locating and comparing gridded model data with remote-sensing observations, Geosci. Model Dev., 8, 911–921, https://doi.org/10.5194/gmd-8-911-2015, 2015. a
Loew, A., Bell, W., Brocca, L., Bulgin, C. E., Burdanowitz, J., Calbet, X., Donner, R. V., Ghent, D., Gruber, A., Kaminski, T., Kinzel, J., Klepp, C., Lambert, J.-C., Schaepman-Strub, G., Schröder, M., and Verhoelst, T.: Validation practices for satellite-based Earth observation data across communities, Rev. Geophys., 55, 779–817, https://doi.org/10.1002/2017RG000562, 2017. a, b
Nappo, C., Caneill, J., Furman, R., Gifford, F., Kaimal, J., Kramer, M., Lockhart, T., Pendergast, M., Pielke, R., and Randerson, D.: Workshop on the representativeness of meteorological observations, June 1981, Boulder, Colorado, B. Am. Meteorol. Soc., 63, 761–764, 1982. a, b
Povey, A. C. and Grainger, R. G.: Known and unknown unknowns: uncertainty estimation in satellite remote sensing, Atmos. Meas. Tech., 8, 4699–4718, https://doi.org/10.5194/amt-8-4699-2015, 2015. a
Ridolfi, M., Ceccherini, S., and Carli, B.: Optimal interpolation method for intercomparison of atmospheric measurements, Opt. Lett., 31, 855–857, https://doi.org/10.1364/OL.31.000855, 2006. a, b
Rodgers, C. D.: Inverse Methods for Atmospheric Sounding, vol. 2 of Series on Atmospheric, Oceanic and Planetary Physics, World Scientific, Singapore, 2000. a, b, c, d, e, f, g, h, i, j, k, l, m, n
Rodgers, C. D. and Connor, B. J.: Intercomparison of remote sounding instruments, J. Geophys. Res., 108, 4116, https://doi.org/10.1029/2002JD002299, 2003. a, b, c, d, e, f, g
Verhoelst, T., Granville, J., Hendrick, F., Köhler, U., Lerot, C., Pommereau, J.-P., Redondas, A., Van Roozendael, M., and Lambert, J.-C.: Metrology of ground-based satellite validation: co-location mismatch and smoothing issues of total ozone comparisons, Atmos. Meas. Tech., 8, 5039–5062, https://doi.org/10.5194/amt-8-5039-2015, 2015. a, b, c
von Clarmann, T.: Validation of remotely sensed profiles of atmospheric state variables: strategies and terminology, Atmos. Chem. Phys., 6, 4311–4320, https://doi.org/10.5194/acp-6-4311-2006, 2006. a, b, c, d, e, f
von Clarmann, T.: Smoothing error pitfalls, Atmos. Meas. Tech., 7, 3023–3034, https://doi.org/10.5194/amt-7-3023-2014, 2014. a, b
von Clarmann, T. and Grabowski, U.: Elimination of hidden a priori information from remotely sensed profile data, Atmos. Chem. Phys., 7, 397–408, https://doi.org/10.5194/acp-7-397-2007, 2007. a, b, c, d, e, f, g, h, i
von Clarmann, T., De Clercq, C., Ridolfi, M., Höpfner, M., and Lambert, J.-C.: The horizontal resolution of MIPAS, Atmos. Meas. Tech., 2, 47–54, https://doi.org/10.5194/amt-2-47-2009, 2009. a
von Clarmann, T., Glatthor, N., and Plieninger, J.: Maximum likelihood representation of MIPAS profiles, Atmos. Meas. Tech., 8, 2749–2757, https://doi.org/10.5194/amt-8-2749-2015, 2015. a