the Creative Commons Attribution 4.0 License.
the Creative Commons Attribution 4.0 License.
 | 26 Sep 2019
| 26 Sep 2019
Gaussian process regression model for dynamically calibrating and surveilling a wireless low-cost particulate matter sensor network in Delhi
Tongshu Zheng
Michael H. Bergin
Ronak Sutaria
Sachchida N. Tripathi
Robert Caldow
David E. Carlson
Wireless low-cost particulate matter sensor networks (WLPMSNs) are transforming air quality monitoring by providing particulate matter (PM) information at finer spatial and temporal resolutions. However, large-scale WLPMSN calibration and maintenance remain a challenge. The manual labor involved in initial calibration by collocation and routine recalibration is intensive. The transferability of the calibration models determined from initial collocation to new deployment sites is questionable, as calibration factors typically vary with the urban heterogeneity of operating conditions and aerosol optical properties. Furthermore, the stability of low-cost sensors can drift or degrade over time. This study presents a simultaneous Gaussian process regression (GPR) and simple linear regression pipeline to calibrate and monitor dense WLPMSNs on the fly by leveraging all available reference monitors across an area without resorting to pre-deployment collocation calibration. We evaluated our method for Delhi, where the PM2.5 measurements of all 22 regulatory reference and 10 low-cost nodes were available for 59 d from 1 January to 31 March 2018 (PM2.5 averaged 138±31 µg m−3 among 22 reference stations), using a leave-one-out cross-validation (CV) over the 22 reference nodes. We showed that our approach can achieve an overall 30 % prediction error (RMSE: 33 µg m−3) at a 24 h scale, and it is robust as it is underscored by the small variability in the GPR model parameters and in the model-produced calibration factors for the low-cost nodes among the 22-fold CV. Of the 22 reference stations, high-quality predictions were observed for those stations whose PM2.5 means were close to the Delhi-wide mean (i.e., 138±31 µg m−3), and relatively poor predictions were observed for those nodes whose means differed substantially from the Delhi-wide mean (particularly on the lower end). We also observed washed-out local variability in PM2.5 across the 10 low-cost sites after calibration using our approach, which stands in marked contrast to the true wide variability across the reference sites. These observations revealed that our proposed technique (and more generally the geostatistical technique) requires high spatial homogeneity in the pollutant concentrations to be fully effective. We further demonstrated that our algorithm performance is insensitive to training window size as the mean prediction error rate and the standard error of the mean (SEM) for the 22 reference stations remained consistent at ∼30 % and ∼3 %–4 %, respectively, when an increment of 2 d of data was included in the model training. The markedly low requirement of our algorithm for training data enables the models to always be nearly the most updated in the field, thus realizing the algorithm's full potential for dynamically surveilling large-scale WLPMSNs by detecting malfunctioning low-cost nodes and tracking the drift with little latency. Our algorithm presented similarly stable 26 %–34 % mean prediction errors and ∼3 %–7 % SEMs over the sampling period when pre-trained on the current week's data and predicting 1 week ahead, and therefore it is suitable for online calibration. Simulations conducted using our algorithm suggest that in addition to dynamic calibration, the algorithm can also be adapted for automated monitoring of large-scale WLPMSNs. In these simulations, the algorithm was able to differentiate malfunctioning low-cost nodes (due to either hardware failure or under the heavy influence of local sources) within a network by identifying aberrant model-generated calibration factors (i.e., slopes close to zero and intercepts close to the Delhi-wide mean of true PM2.5). The algorithm was also able to track the drift of low-cost nodes accurately within 4 % error for all the simulation scenarios. The simulation results showed that ∼20 reference stations are optimum for our solution in Delhi and confirmed that low-cost nodes can extend the spatial precision of a network by decreasing the extent of pure interpolation among only reference stations. Our solution has substantial implications in reducing the amount of manual labor for the calibration and surveillance of extensive WLPMSNs, improving the spatial comprehensiveness of PM evaluation, and enhancing the accuracy of WLPMSNs.
- Article
(11629 KB) -
Supplement
(948 KB) - BibTeX
- EndNote





Low-cost air quality (AQ) sensors that report high time resolution data (e.g., ≤ 1 h) in near real time offer excellent potential for supplementing existing regulatory AQ monitoring networks by providing enhanced estimates of the spatial and temporal variabilities of air pollutants (Snyder et al., 2013). Certain low-cost particulate matter (PM) sensors have demonstrated satisfactory performances when benchmarked against Federal Equivalent Methods (FEMs) or research-grade instruments in some previous field studies (Holstius et al., 2014; Gao et al., 2015; SCAQMD, 2015a–c, 2017a–c; Jiao et al., 2016; Kelly et al., 2017; Mukherjee et al., 2017; Crilley et al., 2018; Feinberg et al., 2018; Johnson et al., 2018; Zheng et al., 2018). Application-wise, low-cost PM sensors have had success in identifying urban fine particle (PM2.5, with a diameter of 2.5 µm and smaller) hotspots in Xi'an, China (Gao et al., 2015), mapping urban air quality with additional dispersion model information in Oslo, Norway (Schneider et al., 2017), monitoring smoke from prescribed fire in Colorado, US (Kelleher et al., 2018), measuring a traveler's exposure to PM2.5 in various microenvironments in Southeast Asia (Ozler et al., 2018), and building up a detailed city-wide temporal and spatial indoor PM2.5 exposure profile in Beijing, China (Zuo et al., 2018).
On the down side, researchers have been plagued by calibration-related issues since the emergence of low-cost AQ sensors. One common brute force solution is initial calibration by collocation with reference analyzers before field deployment and follow-up with routine recalibration. Yet, the transferability of these pre-determined calibrations at collocation sites to new deployment sites is questionable as calibration factors typically vary with operating conditions such as PM mass concentrations, relative humidity (RH), temperature, and aerosol optical properties (Holstius et al., 2014; Austin et al., 2015; Wang et al., 2015; Lewis and Edwards, 2016; Crilley et al., 2018; Jayaratne et al., 2018; Zheng et al., 2018). Complicating this further, the pre-generated calibration curves may only apply for a short term as the stability of low-cost sensors can develop drift or degrade over time (Lewis and Edwards, 2016; Jiao et al., 2016; Hagler et al., 2018). Routine recalibrations which require frequent transit of the deployed sensors between the field and the reference sites are not only too labor intensive for a large-scale network but also still cannot address the impact of urban heterogeneity of ambient conditions on calibration models (Kizel et al., 2018).
As such, calibrating sensors on the fly while they are deployed in the field is highly desirable. Takruri et al. (2009) showed that the interacting multiple model (IMM) algorithm combined with the support vector regression (SVR)–unscented Kalman filter (UKF) can automatically and successfully detect and correct low-cost sensor measurement errors in the field; however, the implementation of this algorithm still requires pre-deployment calibrations. Fishbain and Moreno-Centeno (2016) designed a self-calibration strategy for low-cost nodes with no need for collocation by exploiting the raw signal differences between all possible pairs of nodes. The learned calibrated measurements are the vectors whose pairwise differences are closest in the normalized projected Cook–Kress (NPCK) distance to the corresponding pairwise raw signal differences given all possible pairs over all time steps. However, this strategy did not include reference measurements in the self-calibration procedure, and therefore the tuned measurements were still essentially raw signals (although instrument noise was dampened). An alternative calibration method involves chain calibration of the low-cost nodes in the field with only the first node calibrated by collocation with reference analyzers and the remaining nodes calibrated sequentially by their respective previous node along the chain (Kizel et al., 2018). While this node-to-node calibration procedure proved its merits in reducing collocation burden and data loss during calibration, relocation, and recalibration and accommodating the influence of urban heterogeneity on calibration models, it is only suitable for relatively small networks because calibration errors propagate through chains and can inflate toward the end of a long chain (Kizel et al., 2018).
In this paper, we introduce a simultaneous Gaussian process regression (GPR) and simple linear regression pipeline to calibrate PM2.5 readings of any number of low-cost PM sensors on the fly in the field without resorting to pre-deployment collocation calibration by leveraging all available reference monitors across an area (e.g., Delhi, India). The proposed strategy is theoretically sound since the GPR (also known as Kriging) can capture the spatial covariance inherent in the data and has been widely used for spatial data interpolation (e.g., Holdaway, 1996; Di et al., 2016; Schneider et al., 2017), and the simple linear regression calibration can adjust for disagreements between the low-cost sensor and reference instrument measurements, leading to more consistent spatial interpolation. This paper focuses on the following:
-
quantifying experimentally the daily performance of our dynamic calibration model in Delhi during the winter season based on model prediction accuracy on the holdout reference nodes during leave-one-out cross-validations (CVs) and low-cost node calibration accuracy;
-
revealing the potential pitfalls of employing a dynamic calibration algorithm;
-
examining the sensitivity of our algorithm to the training data size and the feasibility of it for dynamic calibration;
-
demonstrating the ability of our algorithm to auto-detect faulty nodes and auto-correct the drift of nodes within a network via computational simulation, and therefore the practicality of adapting our algorithm for automated large-scale sensor network monitoring; and
-
studying computationally the optimal number of reference stations across Delhi to support our technique and the usefulness of low-cost sensors for extending the spatial precision of a sensor network.
To the best of our knowledge, this is the first study to apply such a non-static calibration technique to a wireless low-cost PM sensor network in a heavily polluted region such as India and is the first to present methods of auto-monitoring dense AQ sensor networks.
2.1 Low-cost node configuration
The low-cost packages used in the present study (dubbed “Atmos”) shown in Fig. 1a were developed by Respirer Living Sciences (http://atmos.urbansciences.in/, last access: 30 November 2018) and cost USD ∼ 300 per unit. The Atmos monitor measures 20.3 cm L ×12.1 cm W ×7.6 cm H, weighs 500 g, and is housed in an IP65 (Ingress Protection rating 65) enclosure with a liquid crystal display (LCD) on the front showing real-time PM mass concentrations and various debugging messages. It includes a Plantower PMS7003 sensor (USD ∼ 25; dimension: 4.8 cm L ×3.7 cm W ×1.2 cm H) to measure PM1, PM2.5, and PM10 mass concentrations, an Adafruit DHT22 sensor to measure temperature and relative humidity, and an ultra-compact Quectel L80 GPS model to retrieve accurate locations in real time. The operating principle and configuration of PMS7003 are similar to its PMS1003, PMS3003, and PMS5003 counterparts and have been extensively discussed in previous studies (Kelly et al., 2017; Zheng et al., 2018; and Sayahi et al., 2019, respectively). The inlet and outlet of PMS7003 were aligned with two slots on the box to ensure unrestricted airflow into the sensor. The PM and meteorology data are read over the serial TTL interface every 3 seconds, aggregated every 1 min to the memory of the device, before being transmitted by a Quectel M66 GPRS module through the mobile 2G cellular network to an online database. The Atmos can also store the data on a local microSD card in case of transmission failure. Users have the option to configure the frequencies of data transfer and logging to 5, 10, 15, 30, and 60 min via a press key on the device and are able to view the settings on the LCD. All components of the Atmos monitors (key parts are labeled in Fig. 1b) are integrated to a custom-designed printed circuit board (PCB) which is controlled by a STMicroelectronics microcontroller (model STM32F051). Each Atmos was continuously powered up by a 5V 2A USB wall charger, but it also comes with a fail-safe 3.7 V–2600 mAh rechargeable Li-ion battery, in the case of power outage, that can last up to 10 h at a 1 min transmission frequency and 20 h at a 5 min frequency.

The Atmos network's server architecture was also developed by Respirer Living Sciences and built on the following open-source components: KairosDB as the primary fast scalable time series database built on Apache Cassandra, custom-made Java libraries for ingesting data and for providing XML-, JSON-, and CSV-based access to aggregated time series data, HTML5 and JavaScript for creating the front-end dashboard, and LeafletJS for visualizing Atmos networks on maps.
Table 1Delhi PM sensor network sites along with the 1 h percentage data completeness with respect to the entire sampling period (i.e., from 1 January 00:00 to 31 March 2018 23:59, Indian standard time, IST; in total 90 d, 2160 h) before and after 1 h missing-data imputation for each individual site. Note that a 10 % increase in the percentage data completeness after 1 h missing-data imputation is equivalent to ∼216 h of 1 h data being interpolated.

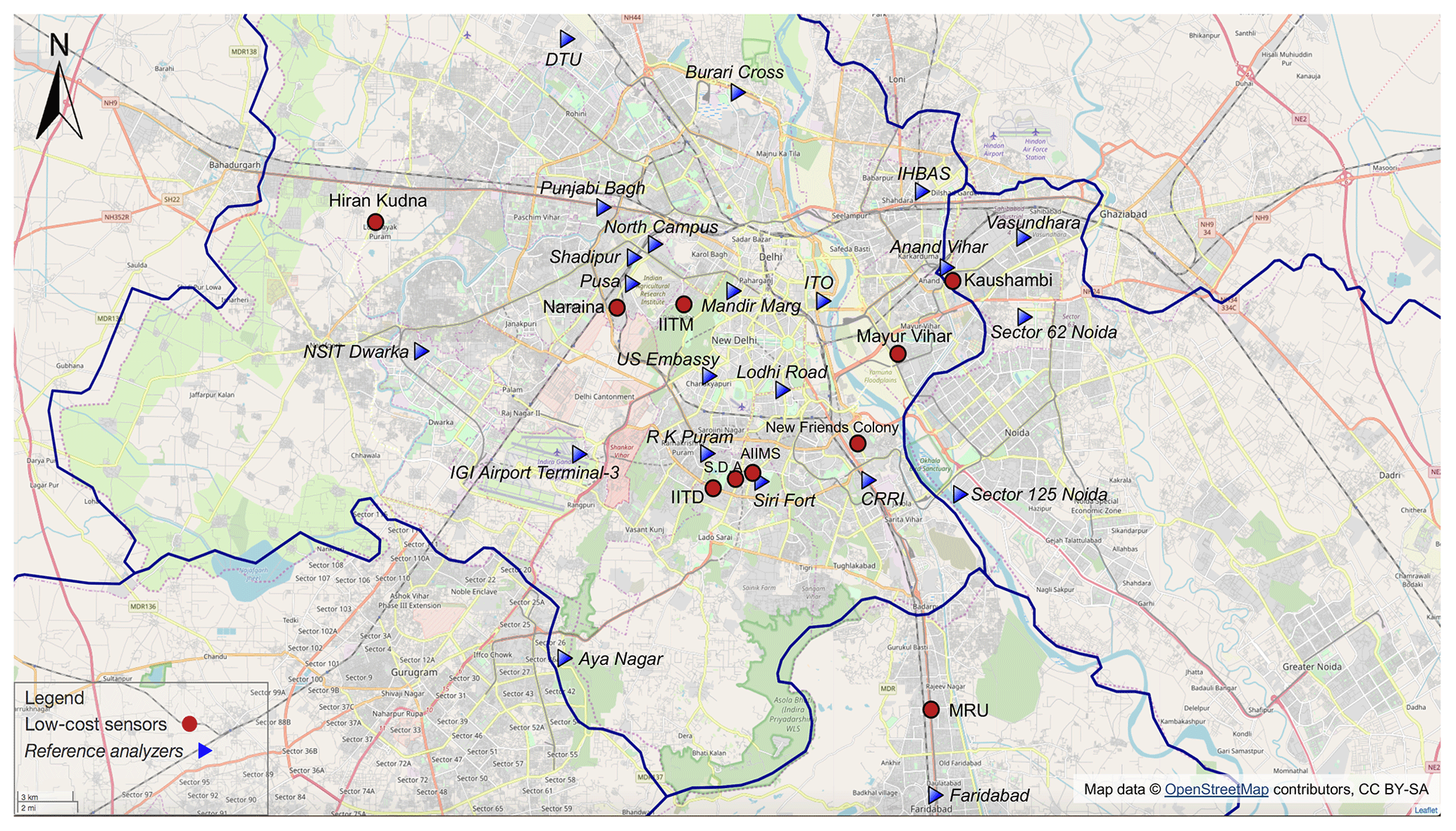
Figure 2Locations of the 22 reference nodes (triangles with italic text) and 10 low-cost nodes (circles) that form the Delhi PM sensor network. ©OpenStreetMap contributors 2019. Distributed under a Creative Commons BY-SA License.
2.2 Data description
2.2.1 Reference PM2.5 data
Hourly ground-level PM2.5 concentrations from 21 monitoring stations operated by the Central Pollution Control Board (CPCB), the Delhi Pollution Control Committee (DPCC), the India Meteorological Department (IMD), the Uttar Pradesh and Haryana State Pollution Control Boards (SPCBs) (https://app.cpcbccr.com/ccr/#/caaqm-dashboard/caaqm-landing, last access: 18 September 2018), and from one monitoring station operated by the U.S. Embassy in New Delhi (https://www.airnow.gov/index.cfm?action=airnow.global_summary#India$New_Delhi, last access: 18 September 2018) were available in our study domain of Delhi, and its satellite cities including Gurgaon, Faridabad, Noida, and Ghaziabad, from 1 January to 31 March 2018 (winter season) and were used as the reference measurements in our Delhi PM sensor network. The topographical, climatic, and air quality conditions of Delhi are well documented by Tiwari et al. (2012, 2015) and Gorai et al. (2018). Briefly, Delhi experiences unusually high PM2.5 concentrations over winter season due to a combination of increased biomass burning for heating, shallower boundary layer mixing height, diminished wet scavenging by precipitation, lower wind speed, and trapping of air pollutants by the Himalayan topology. Figure 2 visualizes the spatial distribution of these 22 reference monitors (triangles with italic text) and Table 1 lists their latitudes and longitudes. No station of the 22 reference monitors is known for regional background monitoring. The complex local built environment in Delhi arising from the densely and intensively mixed land use (Tiwari, 2002) and the significant contributions to air pollution from all vehicular, industrial (small-scale industries and major power plants), commercial (diesel generators and tandoors), and residential (diesel generators and biomass burning) sectors (CPCB, 2009; Gorai et al., 2018) render the PM2.5 concentrations relatively unconnected to the land-use patterns. We removed 104 1 h observations (labeled invalid and missing) from the U.S. Embassy dataset based on its reported QA and QC (quality assurance and quality control) remarks. However, the same procedure was not applied to the remaining 21 Indian government monitoring stations because neither the relevant Indian agencies provided QA and QC remarks or error flags in any of their regulatory monitoring stations' datasets nor can we obtain the QA and QC procedures (e.g., how and how often reference monitors are maintained and calibrated) for these reference monitors. Due to lack of relevant QA and QC information to exclude any measurements, all of the hourly PM2.5 concentrations of the 21 monitoring stations operated by the Indian agencies were assumed to be correct. We would like to highlight this as a potential shortcoming of using the measurements from the Indian government monitoring stations. While mathematically the GPR model can operate without requiring data from all the stations to be non-missing on each day by relying on only each day's non-missing stations' covariance information to make inference, we practically required concurrent measurements of all the stations in this paper to drastically increase the speed of the algorithm (∼10 min to run a complete 22-fold leave-one-out CV, up to ∼20 times faster) by avoiding the expensive computational cost of excessive amount of matrix inversions that can be incurred otherwise. We therefore linearly interpolated the 1 h PM2.5 values for the hours with missing measurements for each station, after which we averaged the hourly data to daily resolution as the model inputs. We validate our interpolation approach in Sect. 3.2.1 by showing that the model accuracies with and without interpolation are statistically the same.
2.2.2 Low-cost node PM2.5 data
Hourly uncalibrated PM2.5 measurements from 10 Atmos low-cost nodes across Delhi between 1 January and 31 March 2018 were downloaded from our low-cost sensor cloud platform. No correction or filter of any kind was applied to the raw signals of the low-cost nodes over the cloud platform before we downloaded the data. Figure 2 shows the sampling locations of these 10 low-cost nodes as circles, and Table 1 specifies their latitudes and longitudes. In our current study, the factors governing the siting of these nodes consist of the ground contact personnel availability, the resource availability such as a strong mobile network signal and 24/7 main power supply, the location's physical accessibility, and some other common criteria for sensor deployment (e.g., locations away from major pollution sources, situated in a place where free flow of air is available, and protected from vandalism and extreme weather). Similar to the pre-processing of the reference PM2.5 data, we linearly interpolated the missing hourly PM2.5 for each low-cost node and then aggregated the hourly data at a daily interval. The comparison of 1 h PM2.5's completeness before and after missing data imputation for both reference and low-cost nodes is detailed in Table 1, and the periods over which data were imputed for each site are illustrated in Fig. S1 in the Supplement. There is no obvious pattern in the data missingness. To remove the prospective outliers such as erroneous surges or nadirs existing in the datasets of the 21 Indian government reference nodes and the 10 low-cost nodes, or to remove unreasonable interpolated measurements introduced during handling the missing data, we employed the Local Outlier Factor (LOF) algorithm with 20 neighbors considered (a number that works well in general) to remove a conservative ∼10 % of the 32-dimensional (22 reference + 10 low-cost nodes) 24 h PM2.5 datasets. The LOF is an unsupervised anomaly detection method that assigns each multi-dimensional data point a LOF score, defined as the ratio of the average local density of its k nearest neighboring data points (k=20 in our study) to its own local density, to measure the relative degree of isolation of the given data point with respect to its neighbors (Breunig et al., 2000). Normal observations tend to have LOF scores near 1, while outliers have scores significantly larger than 1. The LOF therefore identifies the outliers as those multi-dimensional observations with the top x % (x=10 in our study) LOF scores. A total of 59 d of PM2.5 measurements common to all 32 nodes in the network were left (see Fig. S1) and used for our model evaluation.
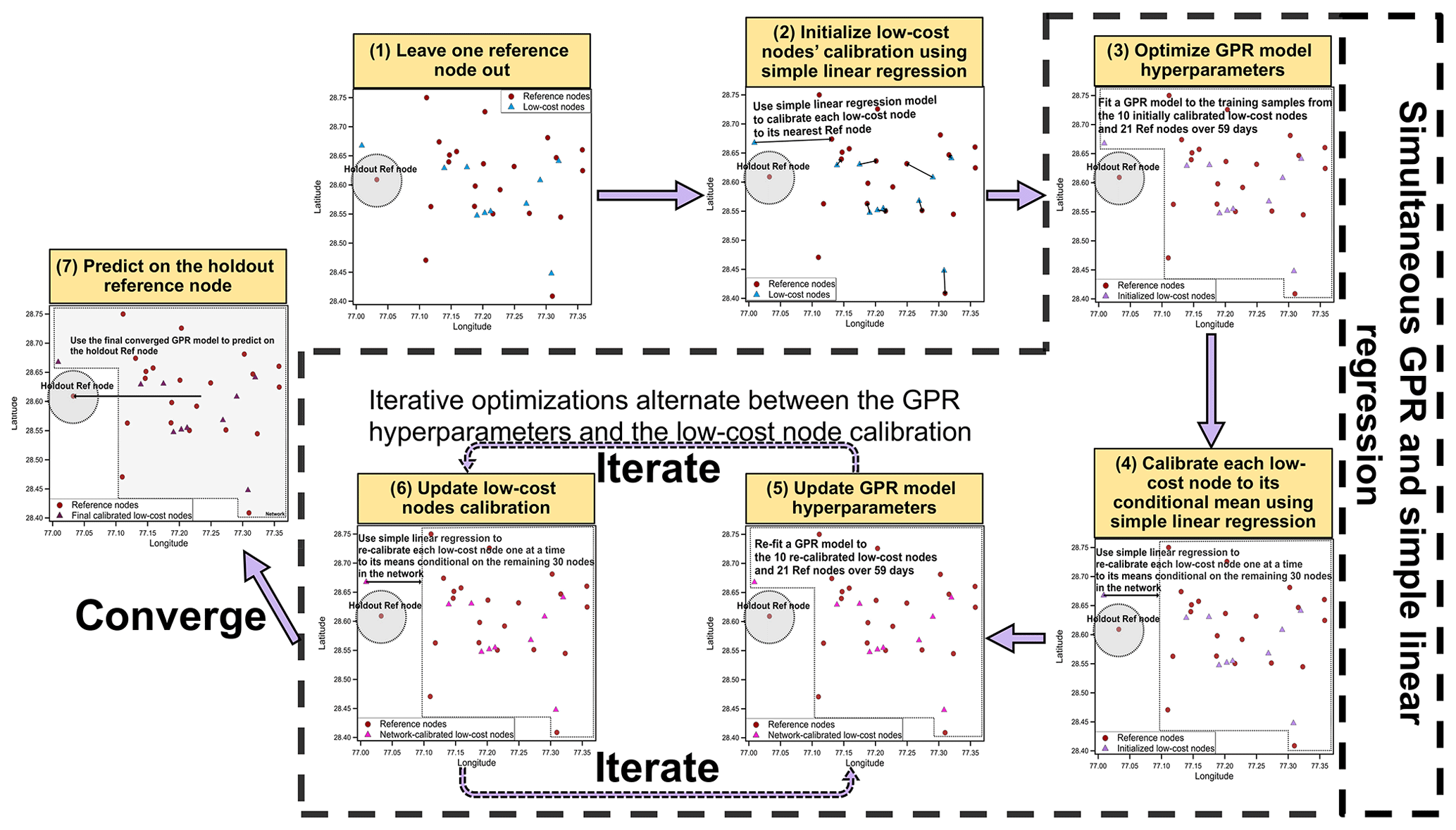
Figure 3The flow diagram illustrating the simultaneous GPR and simple linear regression calibration algorithm. In step one, for each of the 22-fold leave-one-out CVs, one of the 22 reference nodes is held out of modeling for the model predictive performance evaluation in step seven. In step two, fit a simple linear regression model between each low-cost node i and its closest reference node's PM2.5, initialize low-cost node i's calibration model to this linear regression model, and calibrate the low-cost node i using this model. In step three, first initialize the GPR hyperparameters to [0.1, 50, 0.01] and then update the hyperparameters based on the training samples from the 10 initially calibrated low-cost nodes and 21 reference nodes over 59 d. In step four, first compute each low-cost node i's means conditional on the remaining 30 nodes given the optimized GPR hyperparameters, then fit a simple linear regression model between each low-cost node i and its conditional means, update low-cost node i's calibration model to this new linear regression model, and re-calibrate the low-cost node i using this new model. In steps five and six, iterative optimizations alternate between the GPR hyperparameters and the low-cost node calibrations using the approaches described in steps three and four, respectively, until the GPR hyperparameters converged. In step seven, predict the 59 d PM2.5 measurements of the holdout reference node based on the finalized GPR hyperparameters and the low-cost node calibrations.
2.3 Simultaneous GPR and simple linear regression calibration model
The simultaneous GPR and simple linear regression calibration algorithm is introduced here as Algorithm 1. The critical steps of the algorithm are linked to sub-sections under which the respective details can be found. Complementing Algorithm 1, a flow diagram illustrating the algorithm is given in Fig. 3.

2.3.1 Leave one reference node out
Because the true calibration factors for the low-cost nodes are not known beforehand, a leave-one-out CV approach (i.e., holding one of the 22 reference nodes out of modeling each run for model predictive performance evaluation) was adopted as a surrogate to estimate our proposed model accuracy of calibrating the low-cost nodes. For each of the 22-fold CV, 31 node locations (denoted }) were available, where xi is the latitude and longitude of node i. Let yit represent the daily PM2.5 measurement of node i on day t and yt∈ℝ31 denote the concatenation of the daily PM2.5 measurements recorded by the 31 nodes on day t. Given a finite number of node locations, a Gaussian process (GP) becomes a multivariate Gaussian distribution over the nodes in the form of the following:
where μ∈ℝ31 represents the mean function (assumed to be 0 in this study); with represents the covariance function or kernel function and Θ is a vector of the GPR hyperparameters.
For simplicity's sake, the kernel function was set to a squared exponential (SE) covariance term to capture the spatially correlated signals coupled with another component to constrain the independent noise (Rasmussen and Williams, 2006):
where , l, and are the model hyperparameters (to be optimized) that control the signal magnitude, characteristic length scale, and noise magnitude, respectively; Θ ∈ℝ3 is a vector of the GPR hyperparameters , l, and .
2.3.2 Initialize low-cost nodes' (simple linear regression) calibrations
What separates our method from standard GP applications is the simultaneous incorporation of calibration for the low-cost nodes using a simple linear regression model into the spatial model. Linear regression has previously been shown to be effective at calibrating PM sensors (Zheng et al., 2018). Linear regression was first used to initialize low-cost nodes' calibrations (step two in Fig. 3). In this step, each low-cost node i was linearly calibrated to its closest reference node using Eq. (3), where the calibration factors αi (slope) and βi (intercept) were determined by fitting a simple linear regression model to all available pairs of daily PM2.5 mass concentrations from the uncalibrated low-cost node i (independent variable) and its closest reference node (dependent variable). This step aims to bridge disagreements between low-cost and reference node measurements, which can lead to a more consistent spatial interpolation and a faster convergence during the GPR model optimization.
where yi is either a vector of all the daily PM2.5 measurements of reference node i or a vector of all the daily raw PM2.5 signals of low-cost node i; ri is either a vector of all the daily PM2.5 measurements of reference node i or a vector of all the daily calibrated PM2.5 measurements of low-cost node i; and αi and βi are the slope and intercept, respectively, determined from the fitted simple linear regression calibration equation with daily PM2.5 mass concentrations of the uncalibrated low-cost node i as independent variable and PM2.5 mass concentrations of low-cost node i's closest reference node as dependent variable.
2.3.3 Optimize GPR model (hyperparameters)
In the next step (step three in Fig. 3), a GPR model was fit to each day t's 31 nodes (i.e., 10 initialized low-cost nodes and 21 reference nodes) as described in Eq. (4). Prior to the GPR model fitting, all the PM2.5 measurements of the 31 nodes over 59 available days used for GPR model hyperparameters training were standardized. The standardization was performed by first concatenating all these training PM2.5 measurements (from the 31 nodes over 59 d), then subtracting their mean μtraining and dividing them by their standard deviation straining (i.e., transforming all the training PM2.5 measurements to have a 0 mean and unit variance). It is worth noting that assuming the mean function μ∈ℝ31 to be 0 along with standardizing all the training PM2.5 samples in this study is one of the common modeling formulations on the GPR model and also the simplest one. More complex formulations including a station-specific mean function (lack of prior information for this project), a time-dependent mean function (computationally expensive), and a combination of both were not considered for this paper. After the standardization of training samples, the GPR was trained to maximize the log marginal likelihood over all 59 d using Eq. (5) and using an L-BFGS-B optimizer (Byrd et al., 1994). To avoid bad local minima, several random hyperparameter initializations were tried and the initialization that resulted in the largest log marginal likelihood after optimization was chosen (in this paper, Θ = [, l, was initialized to [0.1, 50, 0.01]).
where t ranges from 1 (inclusive) to 59 (inclusive); rt ∈ℝ31 is a vector of all 31 nodes' PM2.5 measurements (calibrated if low-cost nodes) on day t; denotes 31 nodes' locations and xi∈ℝ2 is a vector of the latitude and longitude of node i; μ∈ℝ31 represents the mean function (assumed to be 0 in this study); and with represents the covariance function or kernel function.
where Θ∈ℝ3 is a vector of the GPR hyperparameters , l, and .
2.3.4 Update low-cost nodes' (simple linear regression) calibrations based on their conditional means
Once the optimum Θ for the (initial) GPR was found, we used the learned covariance function to find the mean of each low-cost node i's Gaussian Distribution conditional on the remaining 30 nodes within the network (i.e., ) on day t as described mathematically in Eqs. (6)–(8), and we repeatedly did so until all 59 d of (i.e., were found and then re-calibrated that low-cost node i based on the . The re-calibration was done by first fitting a simple linear regression model to all 59 pairs of daily PM2.5 mass concentrations from the uncalibrated low-cost node i (yi, independent variable) and its conditional mean (, dependent variable) and then using the updated calibration factors (slope αi and intercept βi) obtained from this newly fitted simple linear regression calibration model to calibrate the low-cost node i again (using Eq. 3). This procedure is summarized graphically in Fig. 3 step four and was performed iteratively for all low-cost nodes one at a time. The reasoning behind this step is given in the Supplement. A high-level interpretation of this step is that the target low-cost node is calibrated by being weighted over the remaining nodes within the network and the term computes the weights. In contrast to the inverse distance weighting interpolation which will weight the nodes used for calibration equally if they are equally distant from the target node, the GPR will value sparse information more and lower the importance of redundant information (suppose all the nodes are equally distant from the target node) as shown in Fig. S2.
where and are the daily PM2.5 measurement (s) of the low-cost node i and the remaining 30 nodes on day t; , and are the mean (vector) of the partitioned multivariate Gaussian distribution of the low-cost node i,the remaining 30 nodes, and the low-cost node i conditional on the remaining 30 nodes, respectively, on day t; and , , , , and are the covariance between the low-cost node i and itself, the low-cost node i and the remaining 30 nodes, the remaining 30 nodes and the low-cost node i, the remaining 30 nodes and themselves, and the low-cost node i conditional on the remaining 30 nodes and itself, respectively, on day t.
2.3.5 Optimize alternately and iteratively and converge
Iterative optimizations alternated between the GPR hyperparameters and the low-cost node calibrations using the approaches described in Sect. 2.3.3 and 2.3.4, respectively (Fig. 3 steps five and six, respectively), until the GPR parameters Θ converged. The convergence criteria is the differences in all the GPR hyperparameters between the two adjacent runs below 0.01 (i.e., with , and ).
2.3.6 Predict on the holdout reference node and calculate accuracy metrics
The final GPR was used to predict the 59 d PM2.5 measurements of the holdout reference node (Fig. 3 step seven) following the Cholesky decomposition algorithm (Rasmussen and Williams, 2006) with the standardized predictions being transformed back to the original PM2.5 measurement scale at the end. The back transformation was done by multiplying the predictions by the standard deviation straining (the standard deviation of the training PM2.5 measurements) and then adding back the mean μtraining (the mean of the training PM2.5 measurements). Metrics including root mean square errors (RMSE, Eq. 9) and percent errors defined as RMSE normalized by the average of the true measurements of the holdout reference node in this study (Eq. 10) were calculated for each fold and further averaged over all 22 folds to assess the accuracy and sensitivity of our simultaneous GPR and simple linear regression calibration model.
where yi and are the true and model predicted 59 daily PM2.5 measurements of the holdout reference node i.
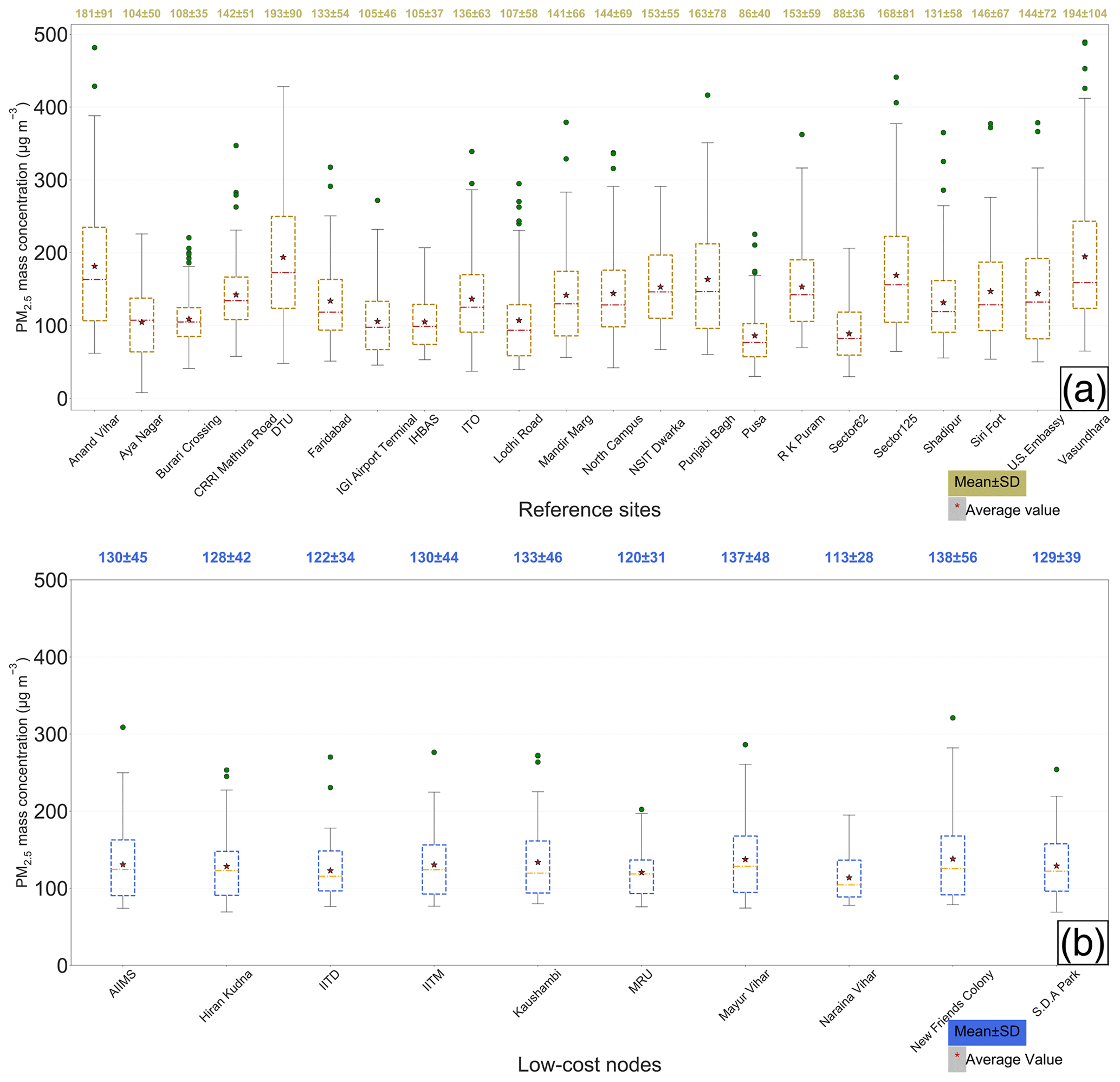
Figure 4(a) Box plots of the 24 h aggregated true ambient PM2.5 mass concentrations measured by the 22 government reference monitors across Delhi from 1 January to 31 March 2018. (b) Box plots of the low-cost node 24 h aggregated PM2.5 mass concentrations calibrated by the optimized GPR model. In both (a) and (b), mean and SD of the PM2.5 mass concentrations for each individual site are superimposed on the box plots.
3.1 Spatial variation of PM2.5 across Delhi
Figure 4a presents the box plot of the daily averaged PM2.5 at each available reference site across Delhi from 1 January to 31 March 2018. The Vasundhara and DTU sites were the most polluted stations with the PM2.5 averaging 194±104 and 193±90 µg m−3, respectively. The Pusa and Sector 62 sites had the lowest mean PM2.5, averaging 86±40 and 88±36 µg m−3, respectively. The Delhi-wide average of the 3-month mean PM2.5 across the 22 reference stations was found to be 138±31 µg m−3. This pronounced spatial variation in mean PM2.5 in Delhi (as reflected by the high SD of 31 µg m−3) coupled with the stronger temporal variation for each station even at a 24 h scale (range: 35–104 µg m−3, see Fig. 4a) caused nonuniform calibration performance of the GPR model across Delhi, as detailed in Sect. 3.2.
3.2 Assessment of GPR model performance
The optimum values of the GPR model parameters including the signal variance (), the characteristic length scale (l), and the noise variance () are shown in Fig. S3. The , l, and from the 22-fold leave-one-out CV averaged 0.53±0.02, 97.89±5.47 km, and 0.47±0.01, respectively. The small variability in all the parameters among all the folds indicates that the model is fairly robust to the different combinations of reference nodes. The learned length scale can be interpreted as the modeled spatial pattern of PM2.5 being relatively consistent within approximately 98 km, suggesting that the optimized model majorly captures a regional trend rather than fine-grained local variations in Delhi.
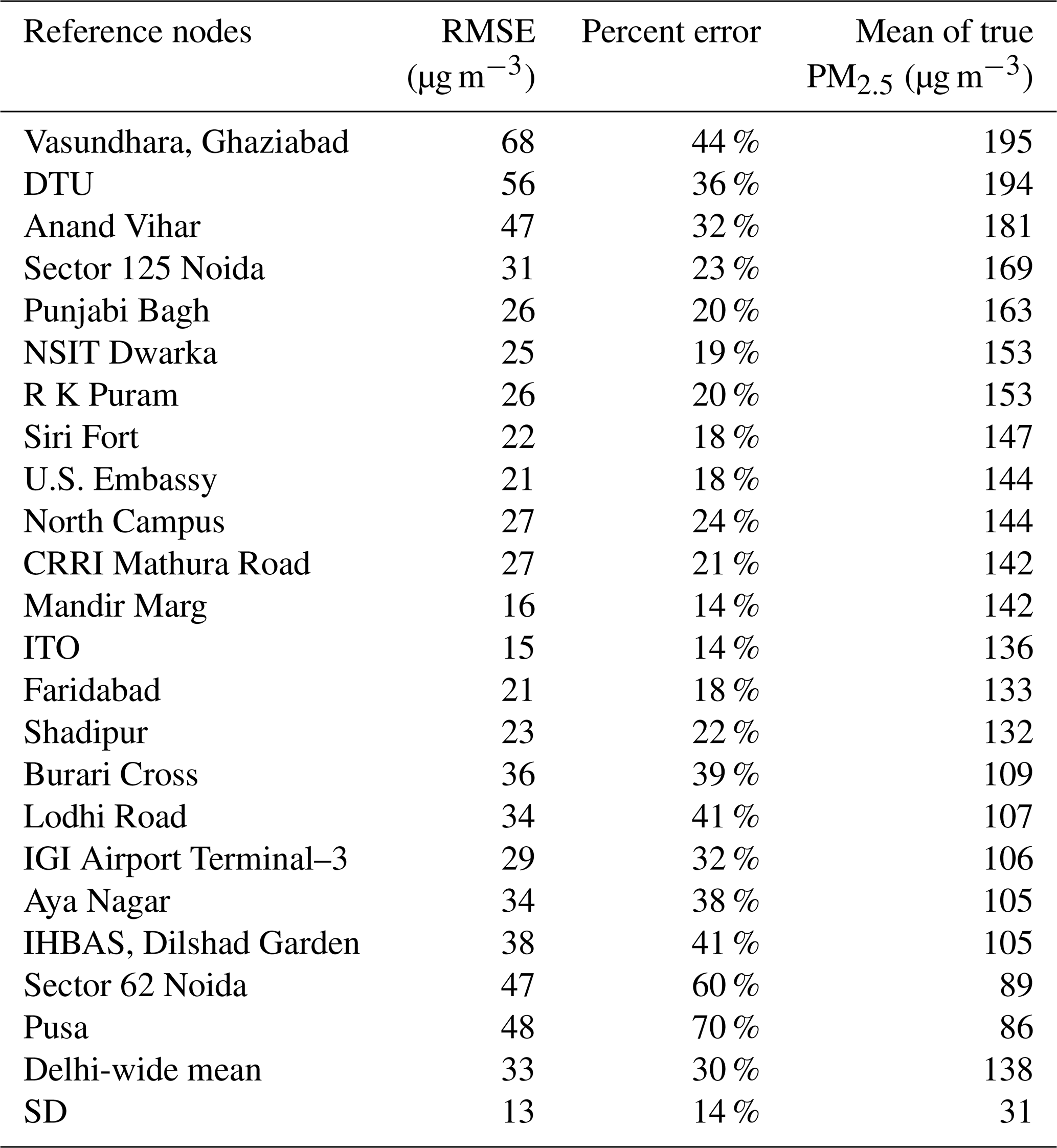
Table 2Summary of the GPR model 24 h performance scores (including RMSE and percent error) for predicting the measurements of the 22 holdout reference nodes across the 22-fold leave-one-out CV when the full sensor network is used. The mean of the true ambient PM2.5 mass concentrations throughout the study (from 1 January to 31 March 2018) for each individual reference node is provided. The reference nodes with the means of true PM2.5 inside the range of (Delhi-wide mean ± SD, i.e., 138±31) are indicated with shading.
3.2.1 Accuracy of reference node prediction
We start by showing the accuracy of model prediction on the 22 reference nodes using leave-one-out CV (when the low-cost node measurements were included in our spatial prediction). Without any prior knowledge of the true calibration factors for the low-cost nodes, the holdout reference node prediction accuracy is a statistically sound proxy for estimating how well our technique can calibrate the low-cost nodes. The performance scores (including RMSE and percent error) for each reference station sorted by the 3-month mean PM2.5 in descending order are listed in Table 2. An overall 30 % prediction error (equivalent to an RMSE of 33 µg m−3) at a 24 h scale was achieved on the reference nodes following our calibration procedure. In this paper, we reported our algorithm's accuracy on the 24 h data only rather than on the 1 h data because real-time reference monitors that are certified as the Federal Equivalent Methods (FEMs) by the U.S. Environmental Protection Agency (EPA) are required to provide results comparable to the Federal Reference Methods (FRMs) only for a 24 h but not a 1 h sampling period. Our algorithm, which essentially relies on the accuracy of the reference measurements, can only calibrate or predict as well as the reference methods measure. Therefore, only the percent error based on the reliable 24 h reference measurements is a fair representation of our algorithm's true calibration/prediction ability. Although the technique is reasonably accurate, especially considering the minimal amount of field work involved, its calibration error is nearly 3 times higher than the error of the low-cost nodes that were well calibrated by collocation with an environmental beta attenuation monitor (E-BAM) in our previous study (error: 11 %; RMSE: 13 µg m−3) under similar PM2.5 concentrations at the same temporal resolution (Zheng et al., 2018). The suboptimal on-the-fly mapping accuracy is a result of the optimized model's ability to simulate only the regional trend well. From a different perspective, the GPR method would have modeled the spatial pattern of PM2.5 in Delhi well had the natural spatial covariance among the nodes not been disturbed by the complex and prevalent local sources there. As a substantiation of the flawed local PM2.5 variation modeling, the reference node mapping accuracy follows a pattern, with relatively high-quality prediction for those nodes whose means were close to the Delhi-wide mean (e.g., Delhi-wide mean ± SD as highlighted with shading in Table 2) and relatively poor prediction for those nodes whose means differed substantially from the Delhi-wide mean (particularly on the lower end).
In this paper, we interpolated the missing 1 h PM2.5 values for all the reference and low-cost stations to fulfill our requirement of concurrent measurements of all the stations. This approach drastically increased the speed of the algorithm (up to ∼20 times faster) by avoiding the expensive computational cost of excessive amount of matrix inversions that can be incurred from relying on only each day's non-missing stations' covariance information to make inference. Here we prove that the interpolation is an appropriate methodology for this paper by demonstrating that the model prediction percent errors for the 22 reference stations with and without interpolation are statistically the same. The comparison of the errors for each station can be found in Table S1 in the Supplement. Table S1 shows that the percent errors for all the stations are essentially the same with only one exception of station Vasundhara whose error without interpolation is 10 % lower than that with interpolation. The Delhi-wide mean percent errors with (30 %) and without interpolation (29 %) are also essentially the same. We further used the Wilcoxon signed-rank test (Wilcoxon, 1945) to prove that the two related paired samples (i.e., the percent errors for the 22 reference stations with and without interpolation) are indeed statistically the same. The Wilcoxon signed-rank test is a nonparametric version of the parametric paired t test (involving two related or matched samples or groups) that requires no specific distribution on the measurements (unlike the parametric paired t test that assumes a normal distribution). We conducted a two-sided test which has the null hypothesis that the percent errors for the 22 reference stations with and without interpolation are the same (i.e., H0: with = without) against the alternative that they are not the same (i.e., H1: with ≠ without). The p value of the test is 0.07. The level of statistical significance was chosen to be 0.05, which means that the null hypothesis (i.e., H0: with = without) cannot be rejected when the p value is 0.07 (above 0.05). Therefore, interpolating missing 1 h PM2.5 data for both reference and low-cost nodes is appropriate for this paper because the accuracies of model prediction on the 22 reference nodes with and without interpolation are not distinct based on the Wilcoxon signed-rank test result.

Figure 5Box plots of the GPR model 24 h performance scores (including RMSE and percent error) for predicting the measurements of the 22 holdout reference nodes across the 22-fold leave-one-out CV under two scenarios – using the full sensor network by including both reference and low-cost nodes and using only the reference nodes for the model construction. Note both scenarios were given the initial parameter values and bounds that maximize the model performance.
It is of particular interest to validate the value of establishing a relatively dense wireless sensor network in Delhi by examining if the addition of the low-cost nodes can truly lend a performance boost to the spatial interpolation among sensor locations. We juxtapose the interpolation performance using the full sensor network (including both the reference and low-cost nodes) with that using only the reference nodes in Fig. 5. In this context, the unnormalized RMSE is less representative than the percent error of the model interpolation performance because of the unequal numbers of overlapping 24 h observations for all the nodes (59 data points) and for only the reference nodes (87 data points). The comparison revealed that the inclusion of the 10 low-cost devices on top of the regulatory grade monitors can reduce mean and median interpolation error by roughly 2 %. While only a marginal improvement with 10 low-cost nodes in the network, the outcome hints that densely deployed low-cost nodes can have great promise of significantly decreasing the amount of pure interpolation among sensor locations, therefore benefitting the spatial precision of a network. We will explore more about the significance of the low-cost nodes for the network performance in Sect. 3.3.3.
3.2.2 Accuracy of low-cost node calibration
Next we describe the technique's accuracy of low-cost node calibration. The model-produced calibration factors are shown in Fig. 6. The intercepts and slopes for each unique low-cost device varied little among all the 22 CV folds, reiterating the stability of the GPR model. The values of these calibration factors resemble those obtained in the previous field work, with slopes comparable to South Coast Air Quality Management District's evaluations on the Plantower PMS models (SCAQMD, 2017a–c) and intercepts comparable to our Kanpur, India post-monsoon study (Zheng et al., 2018).
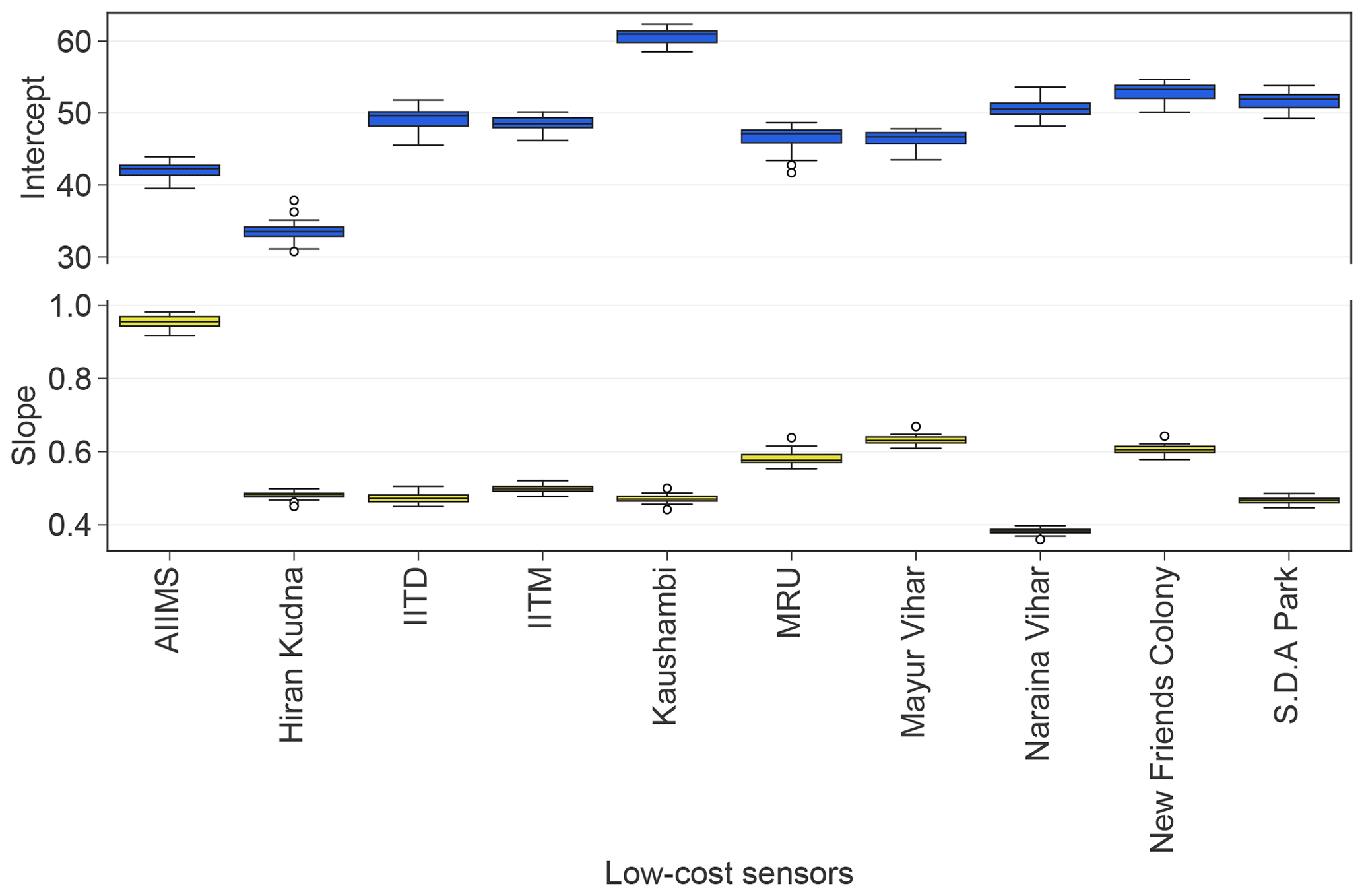
Figure 6Box plots of the learned calibration factors (i.e., intercept and slope) for each individual low-cost node from the 22 optimized GPR models across the 22-fold leave-one-out CV.
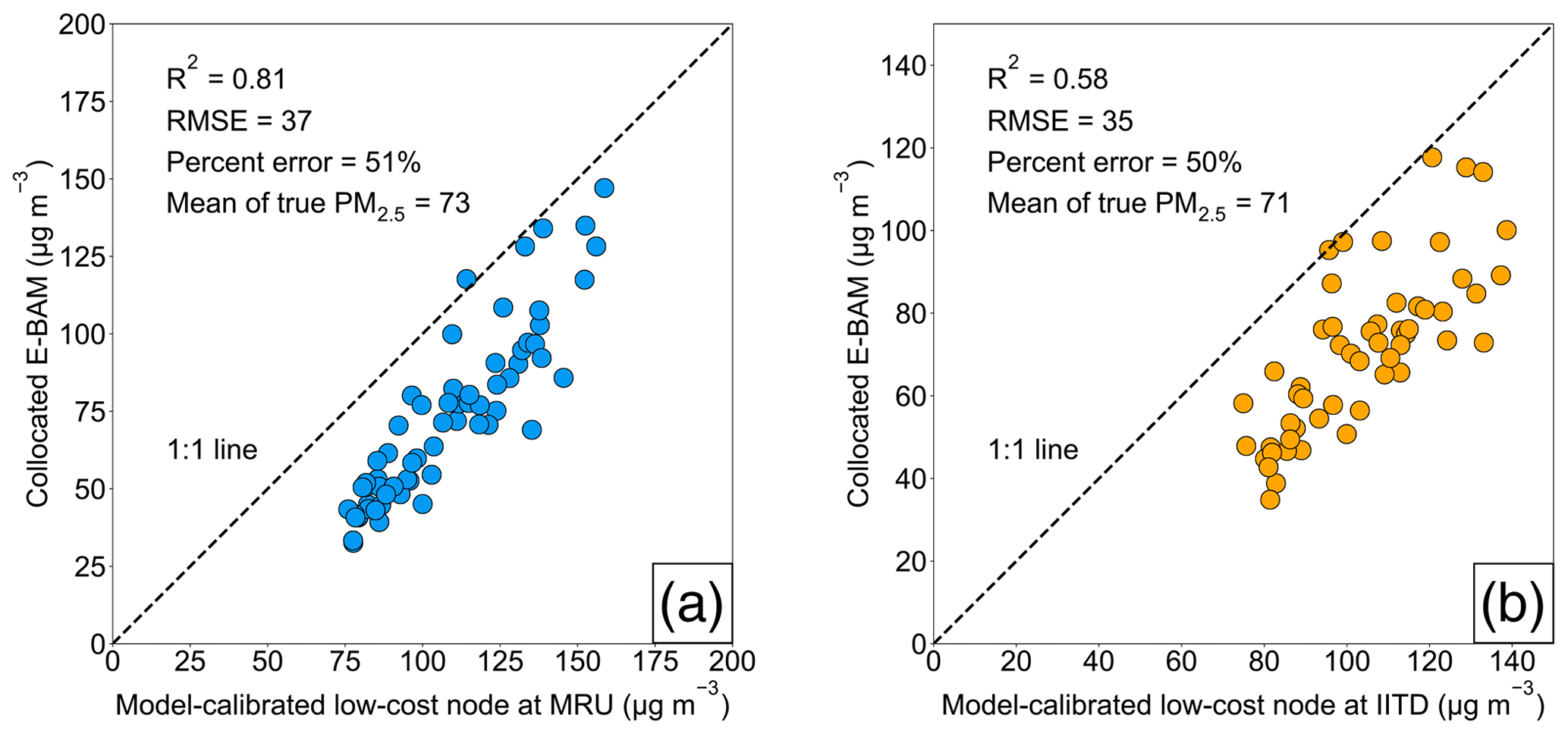
Figure 7Correlation plots comparing the GPR model-calibrated low-cost node PM2.5 mass concentrations to the collocated E-BAM measurements at (a) MRU and (b) IITD sites. In both (a) and (b), correlation of determination (R2), RMSE, percent error, and mean of the true ambient PM2.5 mass concentrations throughout the study (from 1 January to 31 March 2018) are superimposed on the correlation plots.
Two low-cost nodes (i.e., MRU and IITD) were collocated with two E-BAMs throughout the entire study. This allows us to take their model-derived calibration factors and calibrate the corresponding raw values of the low-cost nodes before computing the calibration accuracy based on the ground truth (i.e., E-BAM measurements). Figure 7a and b show the scatterplots of the collocated E-BAM measurements against the model-calibrated low-cost nodes at the MRU and the IITD sites, respectively. The two sites had similarly large calibration errors (∼50 %) because their concentrations were both near the lower end of PM2.5 spectrum in Delhi. These high error rates echo the conditions found at the comparatively clean Pusa and Sector 62 reference sites. The scatterplots also reveal the reason why the technique especially has trouble calibrating low-concentration sites – the technique overpredicted the PM2.5 concentrations at the low-concentration sites to match the levels as if subject to the natural spatial variation. The washed-out local variability after model calibration more obviously manifests in Fig. 4b, which stands in marked contrast to the true wide variability across the reference sites (Fig. 4a). In other words, the geostatistical techniques can calibrate the low-cost nodes dynamically, with the important caveat that it is effective only if the degree of urban homogeneity in PM2.5 is high (e.g., the local contributions are as small a fraction of the regional ones as possible, or the local contributions are prevalent but of similar magnitudes). Otherwise, quality predictions will only apply for those nodes whose means are close to the Delhi-wide mean. Gani et al. (2019) estimated that Delhi's local contribution to the composition-based submicron particulate matter (PM1) was ∼30 to 50 % during winter and spring months. Clearly the huge amount of local influence in Delhi did not fully support our technique.
3.2.3 GPR model performance as a function of training window size
So far, the optimization of both GPR model hyperparameters and the linear regression calibration factors for the low-cost nodes has been carried out over the entire sampling period using all 59 available daily averaged data points. It is of critical importance to examine the effect of time history on the algorithm, by analyzing how sensitive the model performance is to training window size. We tracked the model performance change when an increment of 2 d of data were included in the model training. The model performance was measured by the mean accuracy of model prediction on the 22 reference nodes (within the time period of the training window) using leave-one-out CV, as described in Sect. 3.2.1. Figure 8 illustrates that, throughout the 59 d, the error rate and the standard error of the mean (SEM) remained surprisingly consistent at ∼30 % and ∼3 %–4 %, respectively, regardless of how many 2 d increments were used as the training window size. The little influence of training window size on the GPR model performance is possibly a positive side effect of the algorithm's time-invariant mean assumption, strong spatial smoothing effect, and the additional averaging of the error rates of the 22 reference nodes. The markedly low requirement of our algorithm for training data is powerful in that it enables the GPR model hyperparameters and the linear regression calibration factors to always be nearly the most updated in the field. This helps realize the algorithm's full potential for automatically surveilling large-scale networks by detecting malfunctioning low-cost nodes within a network (see Sect. 3.3.1) and tracking the drift of low-cost nodes (see Sect. 3.3.2) with as little latency as possible.
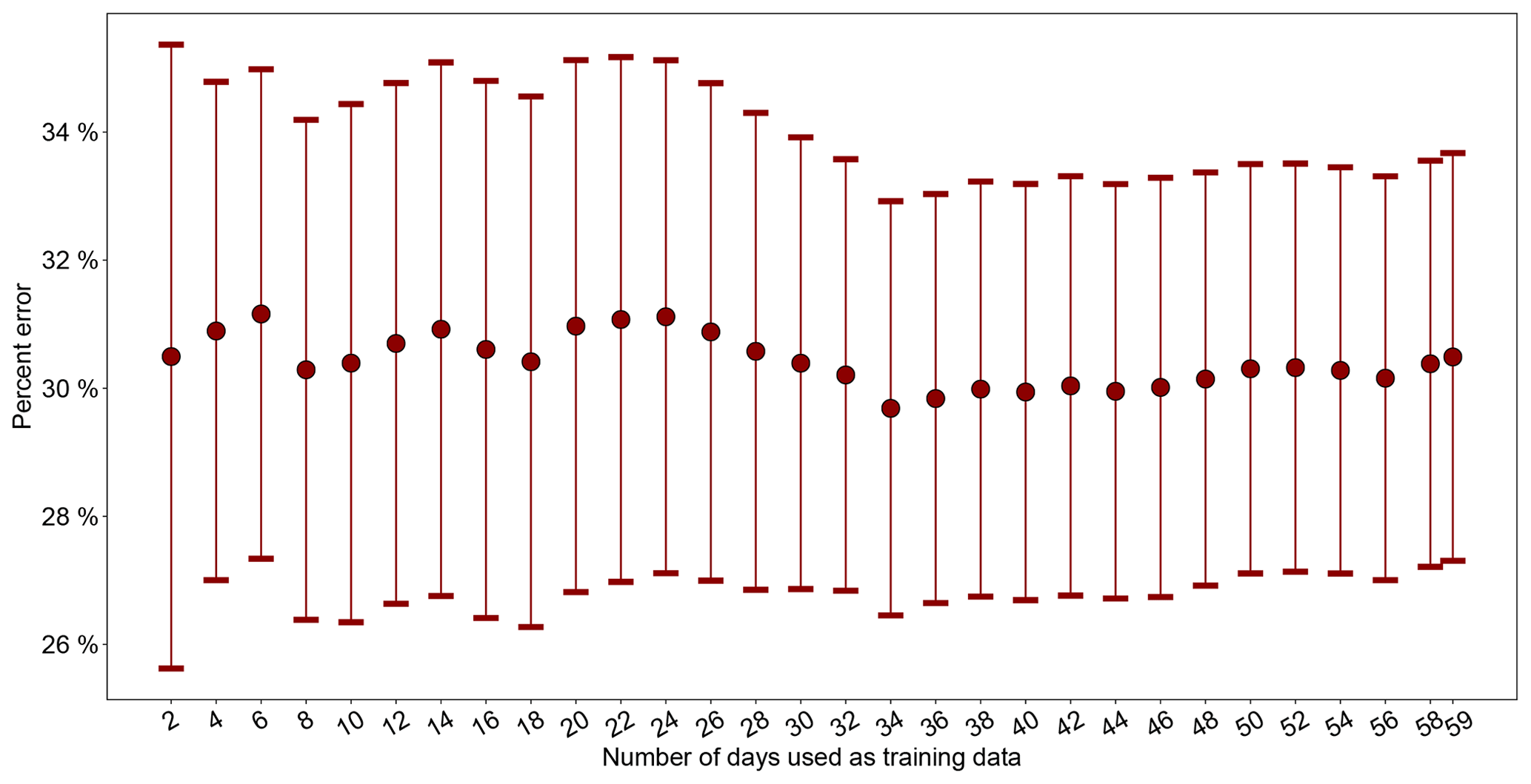
Figure 8The mean percent error rate of GPR model prediction on the 22 reference nodes using leave-one-out CV (see Sect. 3.2.1) as a function of training window size in an increment of 2 d. The error bars represent the standard error of the mean (SEM) of the GPR prediction errors of the 22 reference nodes.
3.2.4 GPR model dynamic calibration performance
The stationary model performance in response to the increase of training data hints that using our method for dynamic calibration or prediction is feasible. We assessed the algorithm's 1 week-ahead prediction performance, by using simple linear regression calibration factors and GPR hyperparameters that were optimized from one week to calibrate the 10 low-cost nodes and predict each of the 22 reference nodes, respectively, in the next week. For example, the first, second, third…, and seventh weeks' data were used as training data to build GPR models and simple linear regression models. These simple linear regression models were then used to calibrate the low-cost nodes in the second, third, fourth…, and eighth weeks, followed by the GPR models to predict each of the 22 reference nodes in that week. The performance was still measured by the mean accuracy of model prediction on the 22 reference nodes using leave-one-out CV, as described in Sect. 3.2.1. We found similarly stable 26 %–34 % dynamic calibration error rates and ∼3 %–7 % SEMs throughout the weeks (see Fig. S4).
3.2.5 Relative humidity (RH) adjustment to the algorithm
We attempted RH adjustment to the algorithm by incorporating an RH term in the linear regression models, where the RH values were the measurements from each corresponding low-cost sensor package's embedded Adafruit DHT22 RH and temperature sensor. However, there was no improvement in the algorithm's accuracy after RH correction. A plausible explanation is one regarding the infrequently high RH conditions during the winter months in Delhi and stronger smoothing effects at longer averaging time intervals (i.e., 24 h). Our previous work (Zheng et al., 2018) suggested that the PMS3003 PM2.5 weights exponentially increased only when RH was above ∼70 %. The Delhi-wide average of the 3-month RH measured by the 10 low-cost sites was found to be 55±15 %. Only 17 % and 6 % of these RH values were greater than 70 % and 80 %, respectively. The infrequently high RH conditions can cause the RH-induced biases to be insignificant. Additionally, our previous work found that even though major RH influences can be found in 1 min to 6 h PM2.5 measurements, the influences significantly diminished in 12 h PM2.5 measurements and were barely observable in 24 h measurements. Therefore, longer averaging time intervals can smooth out the RH biases.
Additionally, while our algorithm was analyzed over the 59 available days in this study, the daily averaged temperature and RH measurements for the entire sampling period (i.e., from 1 January to 31 March 2018, 90 days) were statistically the same as those for the 59 d. To support this statement, we conducted the Wilcoxon rank-sum test, also called Mann–Whitney U test (Wilcoxon, 1945; Mann and Whitney, 1947) on the daily averaged temperature and RH measurements from the Indira Gandhi International (IGI) Airport. The Wilcoxon rank-sum test is a nonparametric version of the parametric t test (involving two independent samples or groups) that requires no specific distribution on the measurements (unlike the parametric t test that assumes a normal distribution). We did not use a paired test here because the two groups had different sample sizes (i.e., 59 and 90, respectively). We conducted a two-sided test which has the null hypotheses that the daily averaged temperature and RH measurements for the 90 d (19±5 ∘C, 59±14 %) and the 59 d (20±5 ∘C, 59±12 %) were the same (i.e., H0: Temperature59 d= Temperature90 d/RH59 d = RH90 d) against the alternatives that they were not the same (i.e., H1: Temperature59 d≠ Temperature90 d/RH59 d≠ RH90 d). The p values for the temperature and RH comparisons are 0.28 and 0.59, respectively. The level of statistical significance was chosen to be 0.05, which means that the null hypotheses (i.e., H0: Temperature59 d= Temperature90 d/RH59 d= RH90 d) cannot be rejected when the p values are both above 0.05. Therefore, the daily averaged temperature and RH measurements from the IGI Airport for the entire sampling period and for the 59 d were not statistically distinct.
3.3 Simulation results
While the exact values of the calibration factors derived from the GPR model fell short of faithfully recovering the original picture of PM2.5 spatiotemporal gradients in Delhi, these values of one low-cost node relative to another in the network (Sect. 3.3.1) or relative to itself over time (Sect. 3.3.2) turned out to be useful in facilitating automated large-scale sensor network monitoring.
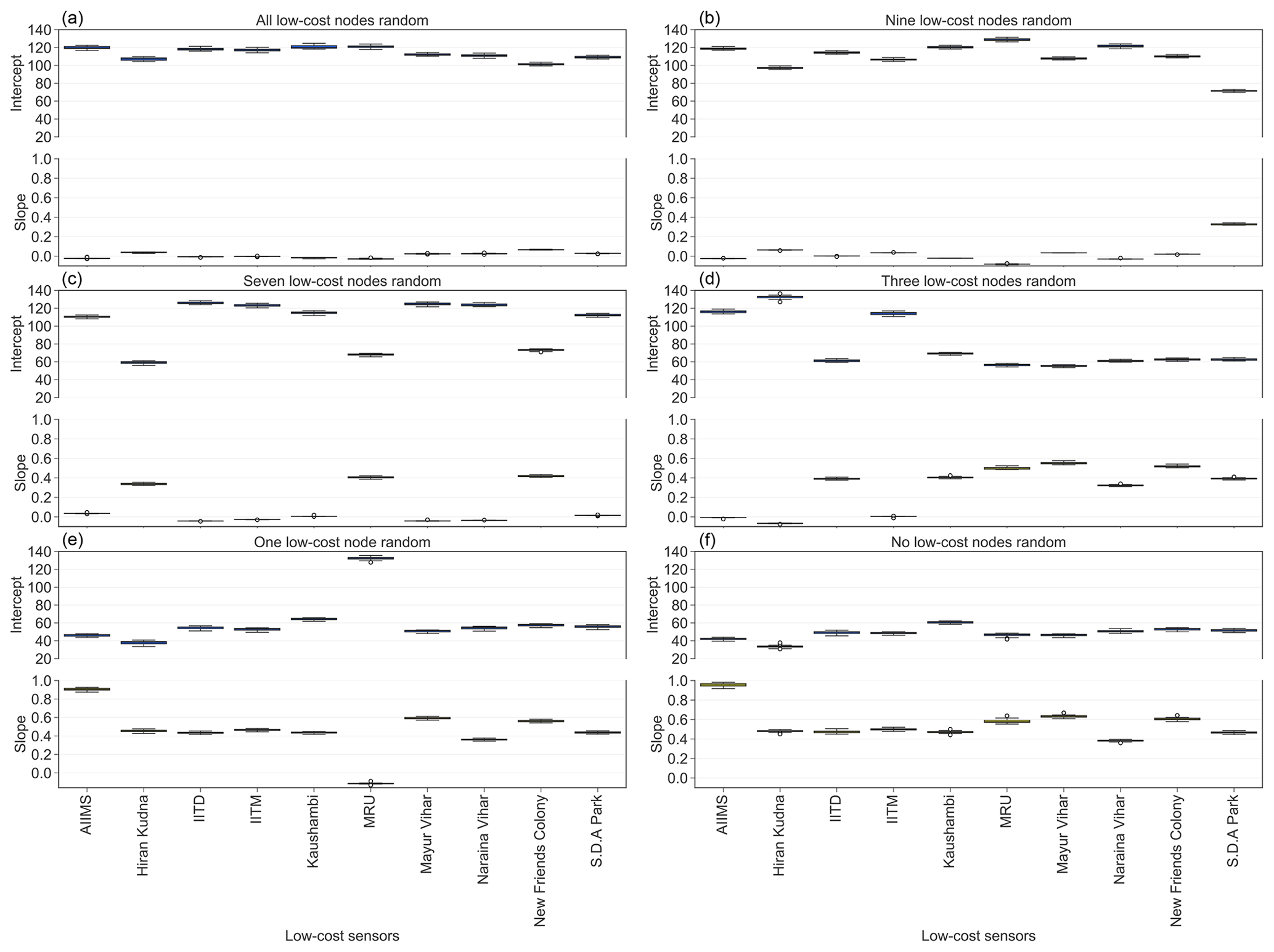
Figure 9Learned calibration factors for each individual low-cost node from the optimized GPR models by replacing measurements of all (a), nine (b), seven (c), three (d), one (e), and zero (f) of the low-cost nodes with random integers bounded by the min and max of the true signals reported by the corresponding low-cost nodes. Note that the nine, seven, three, and one of the low-cost nodes (whose true signals are replaced with random integers) were randomly chosen.
3.3.1 Simulation of low-cost node failure or under heavy influence of local sources
One way to simulate the conditions of low-cost node failure or under heavy influence of local sources is to replace their true signals with values from random number generators so that the inherent spatial correlations are corrupted. In this study, we simulated how the model-produced calibration factors change when all (10), nine, seven, three, and one of the low-cost nodes within the network malfunction or are subject to strong local disturbance. We have three major observations from evaluating the simulation results (Figs. 9 and S5). First, the normal calibration factors are quite distinct from those of the low-cost nodes with random signals. Compared to the normal values (see Fig. 9f), the ones of the low-cost nodes with random signals have slopes close to 0 and intercepts close to the Delhi-wide mean of true PM2.5 in Delhi (most clearly shown in Fig. 9a). Second, the calibration factors of the normal low-cost nodes are not affected by the aberrant nodes within the network (see Fig. 9b,c,d,e,f). These two observations indicate that the GPR model enables automated and streamlined process of instantly spotting any malfunctioning low-cost nodes (due to either hardware failure or under heavy influence of local sources) within a large-scale sensor network. Third, the performance of the GPR model seems to be rather uninfluenced by changing the true signals to random numbers (see Fig. S5, 33 % error rate when all low-cost nodes are random vs. baseline 30 % error rate). One possible explanation is that the prevalent and intricate air pollution sources in Delhi have already dramatically weakened the natural spatial correlations. This means that a significant degree of randomness has already been imposed on the low-cost nodes in Delhi prior to our complete randomness experiment. It is worth mentioning that flatlining is another commonly seen failure mode of our low-cost PM sensors in Delhi. The raw signals of such malfunctioning PM sensors were observed to flatline at the upper end of the sensor output values (typically thousands of µg m−3). The very distinct signals of these flatlining low-cost PM nodes, however, make it rather easy to separate them from the rest of the nodes and filter them out at the early pre-processing stage before analyses and therefore without having to resort to our algorithm. Nevertheless, our not so accurate on-the-fly calibration model has created a useful algorithm for supervising large-scale sensor networks in real time as a by-product.
3.3.2 Simulation of low-cost node drift
We further investigated the feasibility of applying the GPR model to track the drift of low-cost nodes accurately over time. We simulated drift conditions by first setting random percentages of intercept and slope drift, respectively, for each individual low-cost node and for each simulation run. Next, we adjusted the signals of each low-cost node over the entire study period given these randomly selected percentages using Eq. (11). Then, we rebuilt a GPR model based on these drift-adjusted signals and evaluated if the new model-generated calibration factors matched our expected predetermined percentage drift relative to the true (baseline) calibration factors.
where yi, true intercepti, true slopei, percentage intercept drifti, percentage slope drifti, and yi_drift are a vector of the true signals, the standard model-derived intercept, the standard model-derived slope, the randomly generated percentage of intercept drift, the randomly generated percentage of slope drift, and a vector of the drift-adjusted signals, respectively, over the full study period for low-cost node i.
Table 3Comparison of predetermined percentages of drift to those estimated from the GPR model for intercept and slope, respectively, for each individual low-cost node, assuming all (10), six, and two of the low-cost nodes developed various degrees of drift such as significant (11 %–99%), marginal (1 %–10 %), and a balanced mixture of significant and marginal. Note the sensors that drifted, the percentages of drift, and which sensors drifted significantly or marginally are randomly chosen. The results reported under each scenario are based on averages of 10 simulation runs.
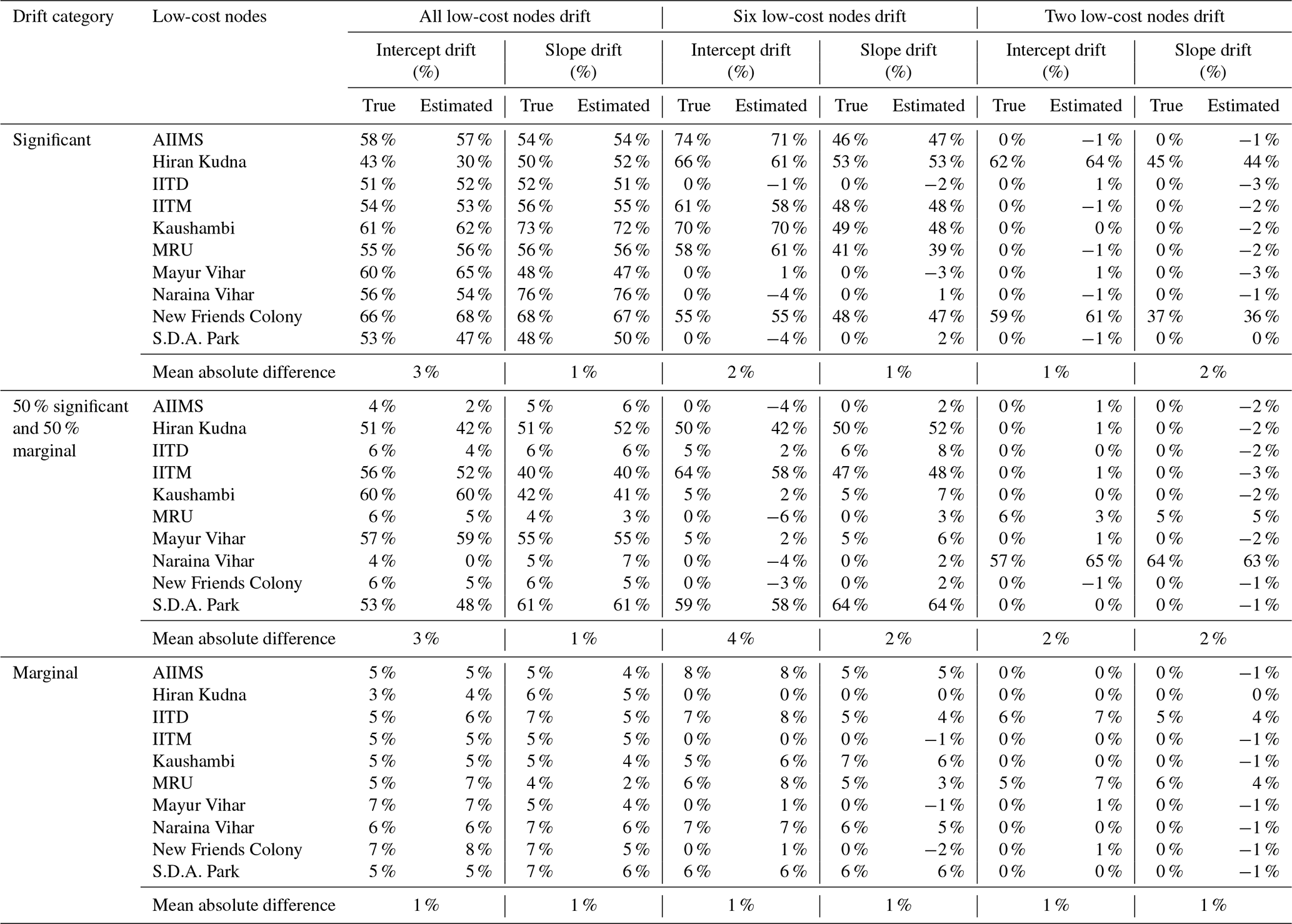
The performance of the model for predicting the drift was examined under a variety of scenarios including the assumption that all (10), eight, six, four, and two of the low-cost nodes developed various degrees of drift such as a significant (11 %–99 %), a marginal (1 %–10 %), and a balanced mixture of significant and marginal. The testing results for 10, six, and two low-cost nodes are displayed in Table 3 and those for eight and four nodes are in Table S2. Overall, the model demonstrates excellent drift predictive power with less than 4 % errors for all the simulation scenarios. The model proves to be most accurate (within 1 % error) when low-cost nodes only drifted marginally regardless of the number of nodes drift. In contrast, significant, and particularly a mixture of significant and marginal drifts, might lead to marginally larger errors. We also notice that the intercept drifts are slightly harder to accurately capture than the slope drifts. Similar to the simulation of low-cost node failure or under strong local impact as described in Sect. 3.3.1, the performance of the model for predicting the measurements of the 22 holdout reference nodes across the 22-fold leave-one-out CV was untouched by the drift conditions (see Fig. S6). This unaltered performance can be attributable to the fact that the drift simulations only involve simple linear transformations as shown in Eq. (11). The high-quality drift estimation has therefore presented another convincing case of how useful our original algorithm can be applied to dynamically monitoring dense sensor networks, as a by-product of calibrating low-cost nodes.
It should be noted that the mode of drift (linear or random drift) will not significantly affect our simulation results. As we demonstrated in Sect. 3.2.3, the performance of our algorithm is insensitive to the training data size. And we believe that models with a similar prediction accuracy should have a similar drift detection power. For example, if the prediction accuracy of the model trained on 59 d of data is virtually the same as accuracy of the model trained on 2 d of data, and if the model trained on 59 d is able to detect the simulated drift, then so should the model trained on 2 d. Then if we reasonably assume that the drift rate remains roughly unchanged within a 2 d window, then the drift mode (linear or random), which only dictates how the drift rate jumps (usually smoothly as well) between any adjacent discrete 2 d windows, does not matter anymore. All that matters is to track that one fixed drift rate reasonably well within those 2 d, which is virtually the same as what we already did with the entire 59 d of data.
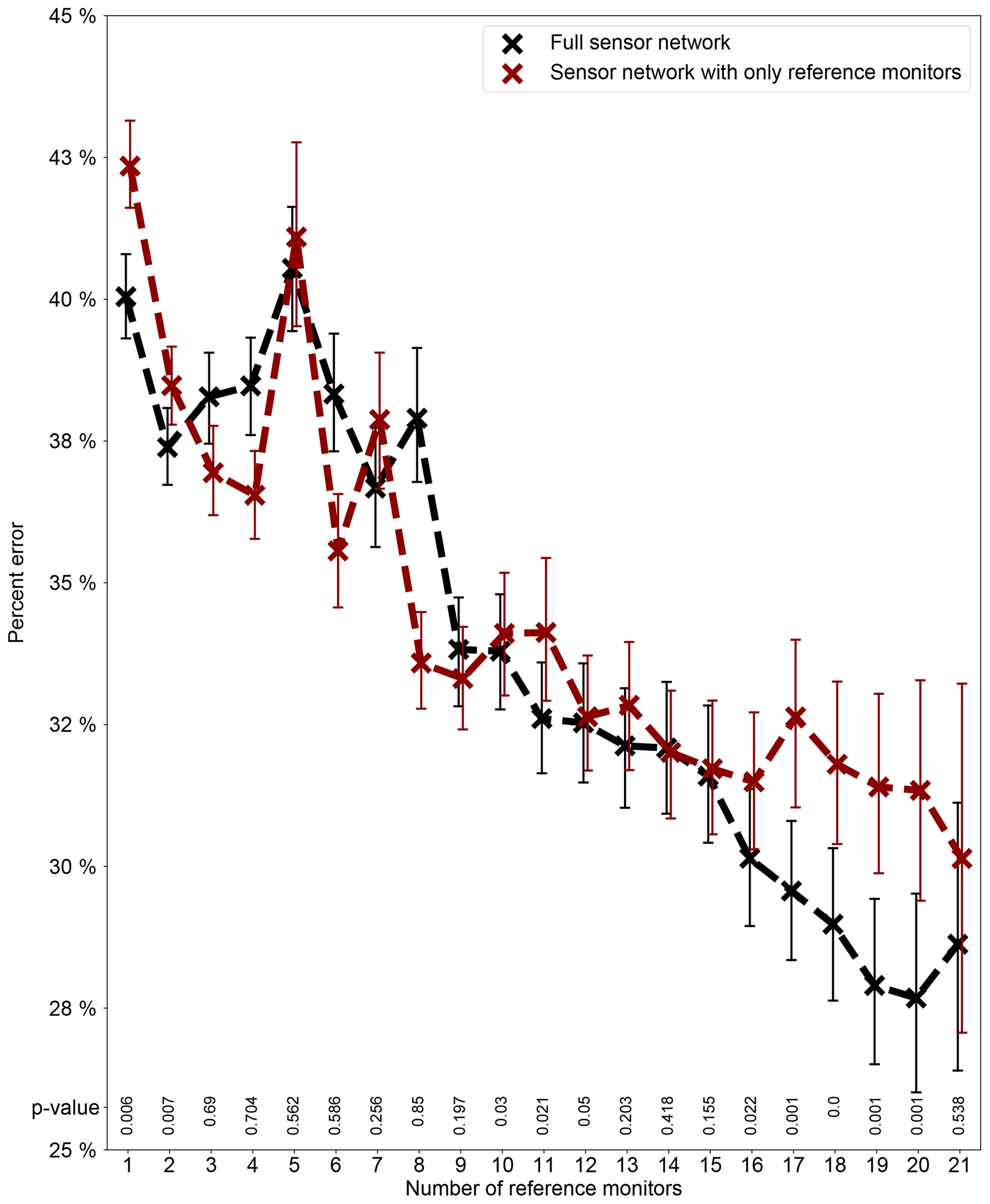
Figure 10Average 24 h percent errors of the GPR model for predicting the holdout reference nodes in the network as a function of the number of reference stations used for the model construction under two scenarios – using the full sensor network information by including both reference and low-cost nodes and using only the reference nodes for the model construction. Note each data point (mean value) is derived from 100 simulation runs. The error bars indicating 95 % confidence interval (CI) of the means are based on 1000 bootstrap iterations. All scenarios were given the initial parameter values and bounds that maximize the model performance. The p value of the Wilcoxon rank-sum test for each reference station number is superimposed, where a p value below 0.05 means that the error when modeling with the 10 low-cost nodes is smaller than the error without them for that reference station number.
3.3.3 Optimal number of reference nodes
Points which remain unaddressed are (1) what the optimum or minimum number of reference instruments is to sustain this technique, and (2) if the inclusion of low-cost nodes can effectively assist in lowering the technique's calibration or mapping inaccuracy. It is interesting to note that optimizing the model's calibration accuracy can not only directly fulfill the fundamental calibration task, but it can also better help the sensor network monitoring capability as an added bonus. To address these two outstanding issues, we randomly sampled subsets of all the 22 reference nodes within the network in increments of one node (i.e., from 1 to 21 nodes) and implemented our algorithm with and without incorporating the low-cost nodes, before finally computing the mean percent errors in predicting all the holdout reference nodes. To get the performance scores as close to truth as possible but without incurring excessive computational cost in the meantime, the sampling was repeated 100 times for each subset size. The calibration error in this section was defined as the mean percent errors in predicting all the holdout reference nodes further averaged over 100 simulation runs for each subset size.
Figure 10 describes the 24 h calibration percent error rate of the model as a function of the number of reference stations used for modeling with and without involving the low-cost nodes. The error rates generally decrease as the number of reference instruments increases (full network: from ∼40 % with 1 node to ∼29 % with 21 nodes; network excluding low-cost nodes: from ∼43 % to ∼30 %) but are somewhat locally variable and most pronounced when five, seven, and eight reference nodes are simulated. These bumps might simply be the result of five, seven, and eight reference nodes being relatively non-ideal (with regard to their neighboring numbers) for the technique, although the possibility of non-convergence due to the limited 100 simulation runs for each scenario cannot be ruled out. The 19 or 20 nodes emerge as the optimum numbers of reference nodes with the lowest errors of close to 28 %, while 17 to 21 nodes all yield comparably low inaccuracies (all below 30 %). The pattern discovered in our research shares certain similarities with Schneider et al. (2017), who studied the relationship between the accuracy of using colocation-calibrated low-cost nodes to map urban AQ and the number of simulated low-cost nodes for their urban-scale air pollution dispersion model and Kriging-fueled data fusion technique in Oslo, Norway. Both studies indicate that at least roughly 20 nodes are essential to start producing an acceptable degree of accuracy. Unlike Schneider et al. (2017), who further expanded the scope to 150 nodes by generating new synthetic stations from their established model and showed a “the more, the merrier” trend of up to 50 stations, we restricted ourselves to only realistic data to investigate the relationship since we suspect that stations created from our model with approximately 30 % errors might introduce large noise, which could misrepresent the true pattern. We agree with Schneider et al. (2017) that such relationships are location specific and cannot be blindly transferred to other study sites.
Lastly, we used the Wilcoxon rank-sum test (Mann–Whitney U test) again to prove that modeling with the 10 low-cost nodes can statistically significantly reduce the uncertainty of spatial interpolation of the reference node measurements in comparison to modeling without them, (at least) when the number of reference stations is optimum. We did not use a paired test here because the reference nodes for algorithm training for each simulation run were randomly chosen. Specifically in our study, for each number of reference stations, the two independent samples (100 replications per sample) are the 100 replications of the mean of the 24 h percent errors (in predicting all the holdout reference nodes) from the 100 repeated random simulations when modeling with and without the low-cost nodes, respectively. We conducted a one-sided test which has the null hypothesis that our model's mean 24 h prediction percent errors with and without including the low-cost nodes are the same (i.e., H0: with = without) against the alternative that the error with the low-cost nodes is smaller than the error without them (i.e., H1: with < without). The p values of the Wilcoxon rank-sum tests are superimposed on Fig. 10. The level of statistical significance was chosen to be 0.05, which means that the null hypothesis (i.e., H0: with = without) can be rejected in favor of the alternative (i.e., H1: with < without) when p values are below 0.05. Figure 10 shows that the accuracy improvement when modeling with the 10 low-cost nodes is statistically significant when the optimum number of reference stations (i.e., 19 or 20) is used. Significant accuracy improvements were also observed for 17 and 18 reference stations that had comparably low prediction errors. Therefore, we conclude that when viewing the entire sensor network in Delhi as a whole system over the entire sampling period, modeling with the 10 low-cost nodes can decrease the extent of pure interpolation among only reference stations, (at least) when the number of reference stations is optimum. The accuracy gains are still relatively minor because of the suboptimal size of the low-cost node network (i.e., 10). We postulate that once the low-cost node network scales up to 100s, the model constructed using the full network information can be more accurate than the one with only the information of reference nodes by considerable margins.
This study introduced a simultaneous GPR and simple linear regression pipeline to calibrate wireless low-cost PM sensor networks (up to any scale) on the fly in the field by capitalizing on all available reference monitors across an area without the requirement of pre-deployment collocation calibration. We evaluated our method for Delhi, where 22 reference and 10 low-cost nodes were available from 1 January to 31 March 2018 (Delhi-wide average of the 3-month mean PM2.5 among 22 reference stations: 138±31 µg m−3), using a leave-one-out CV over the 22 reference nodes. We demonstrated that our approach can achieve excellent robustness and reasonably high accuracy, as it is underscored by the low variability in the GPR model parameters and model-produced calibration factors for low-cost nodes and by an overall 30 % prediction error (equivalent to an RMSE of 33 µg m−3) at a 24 h scale, respectively, among the 22-fold CV. We closely investigated (1) the large model calibration errors (∼50 %) at two low-cost sites (MRU and IITD with a 3-month mean PM2.5 of ∼72 µg m−3) where our E-BAMs were collocated; (2) the similarly large model prediction errors at the comparatively clean Pusa and Sector 62 reference sites; and (3) the washed-out local variability in the model calibrated low-cost sites. These observations revealed that our technique (and more generally the geostatistical techniques) can calibrate the low-cost nodes dynamically, but it is effective only if the degree of urban homogeneity in PM2.5 is high. High urban homogeneity can consist of two scenarios, namely, local contributions are as small a fraction of the regional ones as possible or local contributions are prevalent but of similar magnitudes. Otherwise, quality predictions will only apply for those nodes whose means are close to the Delhi-wide mean. We showed that our algorithm performance is insensitive to training window size as the mean prediction error rate and the standard error of the mean (SEM) for the 22 reference stations remained consistent at ∼30 % and ∼3 %–4 % when an increment of 2 d of data were included in the model training. The markedly low requirement of our algorithm for training data enables the models to always be nearly the most updated in the field, thus realizing the algorithm's full potential for dynamically surveilling large-scale wireless low-cost particulate matter sensor networks (WLPMSNs) by detecting malfunctioning low-cost nodes and tracking the drift with little latency. Our algorithm presented similarly stable 26 %–34 % mean prediction errors and ∼3 %–7 % SEMs over the sampling period when pre-trained on the current week's data and predicting 1 week ahead, and is therefore suitable for dynamic calibration. Despite our algorithm's non-ideal calibration accuracy for Delhi, it holds the promise of being adapted for automated and streamlined large-scale wireless sensor network monitoring and of significantly reducing the amount of manual labor involved in the surveillance and maintenance. Simulations proved our algorithm's capability of differentiating malfunctioning low-cost nodes (due to either hardware failure or under heavy influence of local sources) within a network and its capability of tracking the drift of low-cost nodes accurately with less than 4 % errors for all the simulation scenarios. Finally, our simulation results confirmed that the low-cost nodes are beneficial for the spatial precision of a sensor network by decreasing the extent of pure interpolation among only reference stations, highlighting the substantial significance of dense deployments of low-cost AQ devices for a new generation of AQ monitoring networks.
Two directions are possible for our future work. The first one is to expand both the longitudinal and the cross-sectional scopes of field studies and examine how well our solution works for more extensive networks in a larger geographical area over longer periods of deployment (when sensors are expected to actually drift, degrade, or malfunction). This enables us to validate the practical use of our method for calibration and surveillance more confidently. The second is to explore the infusion of information about urban PM2.5 spatial patterns such as high-spatial-resolution annual average concentration basemap from air pollution dispersion models (Schneider et al., 2017) into our current algorithm to further improve the on-the-fly calibration performance by correcting for the concentration range-specific biases.
The data are available upon request to Tongshu Zheng (tongshu.zheng@duke.edu).
The supplement related to this article is available online at: https://doi.org/10.5194/amt-12-5161-2019-supplement.
TZ, MHB, and DEC designed the study. DEC and TZ participated in the algorithm development. TZ wrote the paper, coded the algorithm, and performed the analyses and simulations. MHB and DEC provided guidance on analyses and simulations and assisted in writing and revising the paper. RS and SNT established, maintained, and collected data from the low-cost sensor network and the two E-BAM sites. TZ collected data from all the regulatory air quality monitoring stations in Delhi. RC provided funding and technical support for the project.
Author Ronak Sutaria is the founder of Respirer Living Sciences Pvt. Ltd, a start-up based in Mumbai, India, which is the developer of the Atmos low-cost AQ monitor. Ronak Sutaria was involved in developing and refining the hardware of Atmos and its server and dashboard, in deploying the sensors, but not involved in data analysis. Author Robert Caldow is the director of engineering at TSI and responsible for the funding and technical support but not responsible for data analysis.
The authors would like to thank CPCB, DPCC, IMD, SPCBs, and AirNow DOS (Department of State) for providing the Delhi 1 h reference PM2.5 measurements used in the current study.
This research has been supported under the Research Initiative for Real-time River Water and Air Quality Monitoring program funded by the Department of Science and Technology, Government of India and Intel®.
This paper was edited by Francis Pope and reviewed by three anonymous referees.
Austin, E., Novosselov, I., Seto, E., and Yost, M. G.: Laboratory evaluation of the Shinyei PPD42NS low-cost particulate matter sensor, PLoS One, 10, 1–17, https://doi.org/10.1371/journal.pone.0137789, 2015.
Breunig, M. M., Kriegel, H. P., Ng, R. T., and Sander, J.: LOF: Identifying Density-Based Local Outliers, available at: http://www.dbs.ifi.lmu.de/Publikationen/Papers/LOF.pdf (last access: 10 December 2018), 2000.
Byrd, R. H., Lu, P., Nocedal, J., and Zhu, C.: A limited memory algorithm for bound constrained optimization, available at: http://users.iems.northwestern.edu/~nocedal/PDFfiles/limited.pdf (last access: 10 December 2018), 1994.
CPCB: Air quality monitoring, emission inventory, and source apportionment studies for Delhi, available at: http://cpcb.nic.in/cpcbold/Delhi.pdf, (last access: 10 December 2018), 2009.
Crilley, L. R., Shaw, M., Pound, R., Kramer, L. J., Price, R., Young, S., Lewis, A. C., and Pope, F. D.: Evaluation of a low-cost optical particle counter (Alphasense OPC-N2) for ambient air monitoring, Atmos. Meas. Tech., 11, 709–720, https://doi.org/10.5194/amt-11-709-2018, 2018.
Di, Q., Kloog, I., Koutrakis, P., Lyapustin, A., Wang, Y., and Schwartz, J.: Assessing PM2.5Exposures with High Spatiotemporal Resolution across the Continental United States, Environ. Sci. Technol., 50, 4712–4721, https://doi.org/10.1021/acs.est.5b06121, 2016.
Feinberg, S., Williams, R., Hagler, G. S. W., Rickard, J., Brown, R., Garver, D., Harshfield, G., Stauffer, P., Mattson, E., Judge, R., and Garvey, S.: Long-term evaluation of air sensor technology under ambient conditions in Denver, Colorado, Atmos. Meas. Tech., 11, 4605–4615, https://doi.org/10.5194/amt-11-4605-2018, 2018.
Fishbain, B. and Moreno-Centeno, E.: Self Calibrated Wireless Distributed Environmental Sensory Networks, Sci. Rep., 6, 1–10, https://doi.org/10.1038/srep24382, 2016.
Gani, S., Bhandari, S., Seraj, S., Wang, D. S., Patel, K., Soni, P., Arub, Z., Habib, G., Hildebrandt Ruiz, L., and Apte, J. S.: Submicron aerosol composition in the world's most polluted megacity: the Delhi Aerosol Supersite study, Atmos. Chem. Phys., 19, 6843–6859, https://doi.org/10.5194/acp-19-6843-2019, 2019.
Gao, M., Cao, J., and Seto, E.: A distributed network of low-cost continuous reading sensors to measure spatiotemporal variations of PM2.5 in Xi'an, China, Environ. Pollut., 199, 56–65, https://doi.org/10.1016/j.envpol.2015.01.013, 2015.
Gorai, A. K., Tchounwou, P. B., Biswal, S., and Tuluri, F.: Spatio-Temporal Variation of Particulate Matter (PM2.5) Concentrations and Its Health Impacts in a Mega City, Delhi in India, Environ. Health Insights, 12, 1–9, https://doi.org/10.1177/1178630218792861, 2018.
Hagler, G. S. W., Williams, R., Papapostolou, V., and Polidori, A.: Air Quality Sensors and Data Adjustment Algorithms: When Is It No Longer a Measurement?, Environ. Sci. Technol., 52, 5530–5531, https://doi.org/10.1021/acs.est.8b01826, 2018.
Holdaway, M. R.: Spatial modeling and interpolation of monthly temperature using kriging, Clim. Res., 6, 215–225, https://doi.org/10.3354/cr006215, 1996.
Holstius, D. M., Pillarisetti, A., Smith, K. R., and Seto, E.: Field calibrations of a low-cost aerosol sensor at a regulatory monitoring site in California, Atmos. Meas. Tech., 7, 1121–1131, https://doi.org/10.5194/amt-7-1121-2014, 2014.
Jayaratne, R., Liu, X., Thai, P., Dunbabin, M., and Morawska, L.: The influence of humidity on the performance of a low-cost air particle mass sensor and the effect of atmospheric fog, Atmos. Meas. Tech., 11, 4883–4890, https://doi.org/10.5194/amt-11-4883-2018, 2018.
Jiao, W., Hagler, G., Williams, R., Sharpe, R., Brown, R., Garver, D., Judge, R., Caudill, M., Rickard, J., Davis, M., Weinstock, L., Zimmer-Dauphinee, S., and Buckley, K.: Community Air Sensor Network (CAIRSENSE) project: evaluation of low-cost sensor performance in a suburban environment in the southeastern United States, Atmos. Meas. Tech., 9, 5281–5292, https://doi.org/10.5194/amt-9-5281-2016, 2016.
Johnson, K. K., Bergin, M. H., Russell, A. G. and Hagler, G. S. W.: Field test of several low-cost particulate matter sensors in high and low concentration urban environments, Aerosol Air Qual. Res., 18, 565–578, https://doi.org/10.4209/aaqr.2017.10.0418, 2018.
Kelleher, S., Quinn, C., Miller-Lionberg, D., and Volckens, J.: A low-cost particulate matter (PM2.5) monitor for wildland fire smoke, Atmos. Meas. Tech., 11, 1087–1097, https://doi.org/10.5194/amt-11-1087-2018, 2018.
Kelly, K. E., Whitaker, J., Petty, A., Widmer, C., Dybwad, A., Sleeth, D., Martin, R., and Butterfield, A.: Ambient and laboratory evaluation of a low-cost particulate matter sensor, Environ. Pollut., 221, 491–500, https://doi.org/10.1016/j.envpol.2016.12.039, 2017.
Kizel, F., Etzion, Y., Shafran-Nathan, R., Levy, I., Fishbain, B., Bartonova, A., and Broday, D. M.: Node-to-node field calibration of wireless distributed air pollution sensor network, Environ. Pollut., 233, 900–909, https://doi.org/10.1016/j.envpol.2017.09.042, 2018.
Lewis, A. and Edwards, P.: Validate personal air-pollution sensors, Nature, 535, 29–31, https://doi.org/10.1038/535029a, 2016.
Mann, H. B. and Whitney, D. R.: On a Test of Whether one of Two Random Variables is Stochastically Larger than the Other, Ann. Math. Stat., 18, 50–60, https://doi.org/10.1214/aoms/1177730491, 1947.
Mukherjee, A., Stanton, L. G., Graham, A. R., and Roberts, P. T.: Assessing the utility of low-cost particulate matter sensors over a 12-week period in the Cuyama valley of California, Sensors, 17, 1805, https://doi.org/10.3390/s17081805, 2017.
Ozler, S., Johnson, K. K., Bergin, M. H. and Schauer, J. J.: Personal Exposure to PM2.5 in the Various Microenvironments as a Traveler in the Southeast Asian Countries, 14, 170–184, https://doi.org/10.3844/ajessp.2018.170.184, 2018.
Rasmussen, C. E. and Williams, C. K. I.: 2. Regression, in: Gaussian Processes for Machine Learning, MIT Press, 8–31, 2006.
Sayahi, T., Butterfield, A., and Kelly, K. E.: Long-term field evaluation of the Plantower PMS low-cost particulate matter sensors, Environ. Pollut., 245, 932–940, https://doi.org/10.1016/j.envpol.2018.11.065, 2019.
Schneider, P., Castell, N., Vogt, M., Dauge, F. R., Lahoz, W. A., and Bartonova, A.: Mapping urban air quality in near real-time using observations from low-cost sensors and model information, Environ. Int., 106, 234–247, https://doi.org/10.1016/j.envint.2017.05.005, 2017.
Snyder, E. G., Watkins, T. H., Solomon, P. A., Thoma, E. D., Williams, R. W., Hagler, G. S. W., Shelow, D., Hindin, D. A., Kilaru, V. J., and Preuss, P. W.: The Changing Paradigm of Air Pollution Monitoring, Environ. Sci. Technol., 47, 11369–11377, https://doi.org/10.1021/es4022602, 2013.
South Coast Air Quality Management District (SCAQMD): Field Evaluation AirBeam PM Sensor, available at: http://www.aqmd.gov/docs/default-source/aq-spec/field-evaluations/ (last access: 10 January 2018), 2015a.
South Coast Air Quality Management District (SCAQMD): Field Evaluation AlphaSense OPC-N2 Sensor, available at: http://www.aqmd.gov/docs/default-source/aq-spec/field-evaluations/alphasense (last access: 10 January 2018), 2015b.
South Coast Air Quality Management District (SCAQMD): Field Evaluation Laser Egg PM Sensor, available at: http://www.aqmd.gov/docs/default-source/aq-spec/field-evaluations/laser (last access: 10 January 2018), 2017a.
South Coast Air Quality Management District (SCAQMD): Field Evaluation Purple Air PM Sensor, available at: http://www.aqmd.gov/docs/default-source/aq-spec/field-evaluations/purpleair (last access: 10 January 2018), 2017b.
South Coast Air Quality Management District (SCAQMD): Field Evaluation Purple Air (PA-II) PM Sensor, available at: http://www.aqmd.gov/docs/default-source/aq-spec/field-evaluations/purple (last access: 10 January 2018), 2017c.
Takruri, M., Challa, S., and Yunis, R.: Data fusion techniques for auto calibration in wireless sensor networks, Inf. Fusion, 132–139, available at: http://ieeexplore.ieee.org/xpls/abs_all.jsp?arnumber=5203880 (last access: 10 December 2018), 2009.
Tiwari, G.: Urban Transport Priorities, Cities, 19, 95–103, available at: http://www.mumbaidp24seven.in/reference/geetam.pdf (last access: 10 December 2018), 2002.
Tiwari, S., Chate, D. M., Pragya, P., Ali, K., and Bisht, D. S. F.: Variations in mass of the PM10, PM2.5 and PM1 during the monsoon and the winter at New Delhi, Aerosol Air Qual. Res., 12, 20–29, https://doi.org/10.4209/aaqr.2011.06.0075, 2012.
Tiwari, S., Hopke, P. K., Pipal, A. S., Srivastava, A. K., Bisht, D. S., Tiwari, S., Singh, A. K., Soni, V. K., and Attri, S. D.: Intra-urban variability of particulate matter (PM2.5 and PM10) and its relationship with optical properties of aerosols over Delhi, India, Atmos. Res., 166, 223–232, https://doi.org/10.1016/j.atmosres.2015.07.007, 2015.
Wang, Y., Li, J., Jing, H., Zhang, Q., Jiang, J., and Biswas, P.: Laboratory Evaluation and Calibration of Three Low-Cost Particle Sensors for Particulate Matter Measurement, Aerosol Sci. Technol., 49, 1063–1077, https://doi.org/10.1080/02786826.2015.1100710, 2015.
Wilcoxon, F.: Individual Comparisons by Ranking Methods, Biometrics Bulletin, 1, 80–83, https://doi.org/10.2307/3001968, 1945.
Zheng, T., Bergin, M. H., Johnson, K. K., Tripathi, S. N., Shirodkar, S., Landis, M. S., Sutaria, R., and Carlson, D. E.: Field evaluation of low-cost particulate matter sensors in high- and low-concentration environments, Atmos. Meas. Tech., 11, 4823–4846, https://doi.org/10.5194/amt-11-4823-2018, 2018.
Zuo, J. X., Ji, W., Ben, Y. J., Hassan, M. A., Fan, W. H., Bates, L., and Dong, Z. M.: Using big data from air quality monitors to evaluate indoor PM2.5 exposure in buildings: Case study in Beijing, Environ. Pollut., 240, 839–847, https://doi.org/10.1016/j.envpol.2018.05.030, 2018.